Archiv nach Kategorie: ‘Forschungsinfrastruktur’
359 Posts; Seite 4
Die Arbeitsgruppe MEPHisto (Modelle, Prozesse und Erklärungen in den historischen Wissenschaften) an der Friedrich-Schiller-Universität Jena sucht zum 1.1.2025 für das Drittmittelprojekt „Forschungsdateninfrastruktur HisQu“ eine/n Doktorand für die Digitale Modellierung von datenintensiven Prozessen der historischen Forschung (m/w/d) mit einem Umfang von 100% der regelmäßigen Arbeitszeit (TV L E 13). Die Stelle ist teilzeitgeeignet und bis zum […]
weiterlesen
Die Deutsche Nationalbibliothek (DNB) und das Leibniz-Institut für Deutsche Sprache (IDS) bieten der Forschung Zugang zu einer besonderen Sammlung zeitgenössischer deutschsprachiger Literatur. Anlässlich des 20-jährigen Jubiläums des Deutschen Buchpreises sind nun alle digital verfügbaren 362 Longlist-Titel zu wissenschaftlichen Zwecken online im Volltext nach sprachlichen Mustern und Strukturen durchsuchbar. Dank der Korpus-Analyseplattform KorAP, bereitgestellt vom Leibniz-Institut […]
weiterlesen

Base4NFDI is an initiative that will develop and offer a set of common shared RDM enabling services to the NFDI community. Base4NFDI supports this via an iterative three-step process, allowing a participatory path to roll-out and, importantly, gaining consensus from the NFDI community along the way. Base4NFDI will have a number of basic services at […]
weiterlesen

Die zweijährlich stattfindenden Wahlen der Koordinationskomitees von Text+ stehen an. Der Wahltermin ist der 6. November 2024. Die Wahl wird über ein elektronisches System erfolgen und eine Stimmabgabe vom Wahltermin bis zum 13. November 2024 ermöglichen. Die Koordinationskomitees (https://text-plus.org/ueber-uns/governance/) sind die zentralen Mitbestimmungsgremien der Text+ Communitys. Sie setzen sich aus drei verschiedenen Scientific Coordination Committees, […]
weiterlesen

Das TextGrid Repository ist ein digitales Langzeitarchiv für geisteswissenschaftliche Forschungsdaten, das einen umfangreichen, durchsuch- und nachnutzbaren Bestand an Texten und Bildern liefert. Es ist an den Grundsätzen von Open Access und den FAIR-Prinzipien orientiert und fokussiert sich auf Texte in XML TEI, um vielfältige Szenarien der Nachnutzung zu unterstützen. Für Forschende bietet das TextGrid Repository […]
weiterlesen

Seit 2014 sammelt correspSearch die Metadaten von edierten Briefen und stellt sie zur projektübergreifenden Recherche bereit. Pünktlich zum runden Geburtstag gibt es jetzt neue Features: Visualisierungen, Volltextsuche und einen SPARQL-Endpoint. Über 270.000 edierte Briefe sind recherchierbar. Grund genug, nicht nur die neuen Funktionen vorzustellen, sondern auch zurück zu blicken und zu schauen, was noch kommt.
weiterlesen
Am 10. und 11. Oktober 2024 trifft sich das Text+ Konsortium zu einer Konferenz mit allen Mitarbeitenden und Interessierten, darunter auch Delegierte aus Fachverbänden und -verbünden, um sich über den Projektfortschritt und die aktuellen Entwicklungen auszutauschen. Die diesjährige Konferenz zum Thema „Große Sprachmodelle (Large Language Models, LLMs) und deren Nutzung“ findet in den Räumen des […]
weiterlesen
Der Bereich „Digitale Forschungsinfrastrukturen“ der FUB-IT an der Freien Universität Berlin stellt mit dem Open Encyclopedia System eine webbasierte Plattform zur Erstellung und Publikation von wissenschaftlichen Online-Referenzwerken im Open Access bereit. Im Rahmen der auf zwei Jahre befristeten Stelle (70% E13 TV-L) sollen tragfähige Strukturen für den Austausch zwischen OES-Anwender*innen und für die systematische Bedarfserhebung […]
weiterlesen
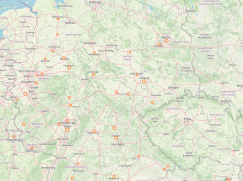
Die Etablierung der Digital Humanities anhand der Ausschreibung und Besetzung von DH-Professuren zu verfolgen bietet sich an. Die hierfür vorliegenden Daten wurden nun für die raum-zeitliche Visualisierung im DARIAH-DE Geo-Browser aufbereitet und zur Verfügung gestellt.
weiterlesen

While the DARIAH Annual Event 2024 in Lisbon is still fresh in our minds, we are already looking forward to next year’s meeting: The DARIAH Annual Event 2025 will be held from June 17-20 in Göttingen, hosted by the Göttingen State and University Library (SUB Göttingen), with the main conference days on June 18–20 (Wednesday […]
weiterlesen