Archiv nach Kategorie: ‘Tool/Service’
65 Posts; Seite 1
Liebe ediarum-Community, liebe ediarum-Interessierte, liebe Kolleg:innen! im Namen des Konsortiums Text+ der Nationalen Forschungsdateninfrastruktur (NFDI) und des ediarum-Teams an der Berlin-Brandenburgischen Akademie der Wissenschaften (BBAW) laden wir Sie herzlich zum nächsten virtuellen ediarum.MEETUP ein: am Montag, den 13. Juli 2026, 11:00 Uhr s.t. Martina Gödel und Johannes Ioannu aus der TELOTA-Abteilung der BBAW stellen das […]
weiterlesen
Recogito ist eine Webumgebung, mit der man in Texten und Bildern Orte, Personen und Ereignisse einfach semantisch auszeichnen kann. Die Dokumente können gemeinsam bearbeitet und Orte bereits während der Annotation auf Karten angezeigt werden. Die Annotationen können in einer Vielzahl von Formaten exportiert werden, um dann weitere Schritte in GIS, Gephi oder in digitalen Editionen […]
weiterlesen
Im Rahmen des Praxislabors 2026 zeigt dir Olaf Simons, wie du mit Wikibase eigene Datenprojekte umsetzen und dich mit bestehenden Wissensnetzwerken wie Wikidata oder FactGrid verbinden kannst.Der Workshop richtet sich an alle, die erste Schritte mit strukturierten Daten und Knowledge Graphen machen wollen. 📅 07.05.2026🕗 20:00 – 21:30 Uhr👉 Alle Infos & Details im Blog: […]
weiterlesen

Der Webservice correspSearch, der historische Briefe durchsuchbar macht und vernetzt, hat einen wichtigen Meilenstein erreicht. Mit der jüngsten Integration der Briefe an Helmina von Chézy, die durch ein Explorationsprojekt an der Berlin-Brandenburgischen Akademie der Wissenschaften (BBAW) ermöglicht wurde, weist die Plattform nun mehr als 400.000 Metadatensätze von edierten oder wissenschaftlich erschlossenen Briefen nach. Initiiert […]
weiterlesen
Liebe ediarum-Community, liebe ediarum-Interessierte, liebe Kolleg:innen! im Namen des Konsortiums Text+ der Nationalen Forschungsdateninfrastruktur (NFDI) und des ediarum-Teams an der Berlin-Brandenburgischen Akademie der Wissenschaften (BBAW) laden wir Sie herzlich zum nächsten virtuellen ediarum.MEETUP ein: am Montag, den 24. November 2025, 11:00 Uhr s.t. Marcus Lampert aus der TELOTA-Abteilung der BBAW stellt ein neues ediarum-Modul vor: […]
weiterlesen
Wir möchten Sie herzlich zur nächsten Veranstaltung unserer Werkstattreihe Standardisierung einladen: Jennifer Ecker, Pia Schwarz und Rebecca Wilm werden DeReKo vorstellen und freuen sich auf die Diskussion mit uns: https://events.gwdg.de/event/1024/. DeReKo Das IDS beheimatet viele Daten und Tools für die Forschung mit insbesondere deutschsprachige Daten. Unter anderem besteht die Möglichkeit, große, annotierte Korpora zu durchsuchen, ein […]
weiterlesen
Liebe ediarum-Community, liebe ediarum-Interessierte, liebe Kolleg:innen! im Namen des Konsortiums Text+ der Nationalen Forschungsdateninfrastruktur (NFDI) und des ediarum-Teams an der Berlin-Brandenburgischen Akademie der Wissenschaften (BBAW) sowie in Kooperation mit der Gender & Data-Arbeitsgruppe der BBAW laden wir Sie herzlich zum nächsten virtuellen ediarum.MEETUP ein: am Montag, den 14. Juli 2025, 11:00 Uhr s.t. Zum Thema […]
weiterlesen
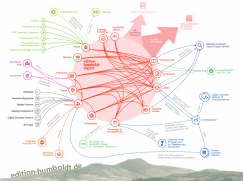
Christian Thomas und Stefan Dumont von der Berlin-Brandenburgischen Akademie der Wissenschaften stellten am 22. Mai 2025 die edition humboldt digital im Rahmen der „Werkstattreihe Standardisierung“ des NFDI-Konsortiums Text+ vor und gaben einen Einblick in ihre Arbeit. Sie reflektierten ihren Umgang mit Standards und deren Bedeutung für die Entwicklung der Edition. Der Werkstattbericht des Editionsprojekts […]
weiterlesen
Wir möchten Sie herzlich zur nächsten Veranstaltung unserer Werkstattreihe Standardisierung einladen: Felix Helfer (SAW) wird INSeRT vorstellen und freut sich auf die Diskussion mit Ihnen: https://events.gwdg.de/event/1022/. Eine Übersicht über alle weiteren Termine der Werkstattreihe und die Anmeldemöglichkeiten finden Sie hier. Und leiten Sie diese Einladung auch gern an andere Interessierte weiter! Worum geht es in der […]
weiterlesen
Im Namen des Konsortiums Text+ der Nationalen Forschungsdateninfrastruktur (NFDI) und des ediarum-Teams an der Berlin-Brandenburgischen Akademie der Wissenschaften (BBAW) sowie in Kooperation mit der Gender & Data-Arbeitsgruppe der BBAW freuen wir uns, das nächste virtuelle ediarum.Meetup anzukündigen: Datum: 14. Juli 2025* Ort: virtuell Zeit: 11:00 – 12:30 Uhr Thema: Encoding Gender Neben einer Einführung in […]
weiterlesen