Die digitale Erfassung von mittelalterlichen Rechtsgeschäften – Beschreibung der semistrukturierten XML-Datenbank db_for_medieval_legal_transactions
Die in diesem Artikel vorgestellte semistrukturierte XML-Datenbank ist auf die Erfassung von mittelalterlichen und frühneuzeitlichen Rechtsgeschäften konzipiert und basiert auf den Konventionen der Text Encoding Initiative (TEI).1 Der Artikel ist als PDF downloadbar DB_Presentation. Dieser Beitrag steht unter der Creative Commons-Lizenz CC BY-NC-SA 4.0.
1. Entstehungszusammenhang
Die Einsicht in die Notwendigkeit einer solchen Datenbank beruht auf den Erfahrungen meiner Masterarbeit ‚Immobilientransfers in Wien in den Jahren 1360-1373.‘ Die hier angewandte Methode der Excel-Tabelle hatte sich aufgrund der Menge der erfassten Informationen als nicht mehr praktikabel herausgestellt. Nach einer kurzen Beschäftigung mit relationalen Datenbanken, begann ich mit der Konzeptionierung einer semistrukturierten Graphen-Datenbank auf XML-Basis. Hierbei kam mir die parallele Beschäftigung mit den monasterium.net inhärenten Auszeichnungsmöglichkeiten (EditMOM 3) im Zuge des Projekts ‚Stadt und Gemeinschaft. Schenkungen und Stiftungen als Quellen sozialer Beziehungsgeflechte im spätmittelalterlichen Wien‘ unter der Leitung von Christina Lutter (Univ. Wien) zu Hilfe. Bei dieser Arbeit (erfasst wurden bisher insg. 1.500 Urkunden in Regestenform) wurde mir einerseits die Strukturierung von Datenerfassungen näher gebracht, andererseits aber auch die Begrenztheit der Auszeichnungsfunktionen und die Wichtigkeit der systematischen Entwicklung derselben im Zuge eines Forschungsprozesses deutlich.
Bis zum Herbst 2020 war die für meine Dissertation notwendige full-version des ‚Datenerfassungschemas’ entwickelt, welche ich als light-version für das Projekt Stadt und Gemeinschaft adaptiert hatte.2
Beide Versionen sind mittlerweile mehrmals durch Auswertungen getestet und evaluiert worden. Die light-version wurde auch bereits in Lehrveranstaltungen verwendet. Die Evaluierung des Erfassungsschemas und des Arbeitsprozesses geschah neben der Erfassung zur Dissertation im Zuge des intensiven Austauschs mit meinen Kollegen Herbert Krammer und Daniel Frey, sowie der technischen Zusammenarbeit mit Jan Bigalke im Rahmen des erwähnten Projektes. Als Quellen zur Entwicklung dienten die Wiener Grundbücher (Satzbuch CD) und die Regesten aus den ‚Quellen zur Geschichte der Stadt Wien‘.3 Erstere wurden unter meiner Mitarbeit digital ediert,4 letztere stehen auf monasterium.net zur Verfügung.5
Diese unterschiedliche Zusammensetzung der Quellen zu mittelalterlichen Rechtsgeschäften ermöglichte die Konzeption eines für zahlreiche Quellengattungen zu Rechtsgeschäften anwendbaren Erfassungsschemas. Der Anspruch war die in beiden Quellentypen enthaltenen Informationen zu Personen, Orten und Institutionen, sowie repräsentative, berufliche, amtliche, freundschaftliche, titulierte, verwandtschaftliche, besitzrechtliche, geschäftliche und topographischen Bezeichnungen und Verknüpfungen systematisch zu erfassen und auszuwerten.
Die nachfolgenden Artikel beschreibt dieses allgemeine Erfassungsschema und veranschaulicht mögliche Auswertungsoptionen anhand von Beispielen aus den erwähnten Quellen (auf Basis des Probeerfassungs-Jahres 1448). Spezifische Anpassungen des Schemas an die unterschiedlichen Rechtsgeschäftstypen werden hier nicht genauer erläutert, werden sich aber z.T. in den entsprechenden online-Handbüchern (der Projekte) befinden.
2. Die zentralen Elemente – der Aufbau
Zentrale Analyseeinheiten (entities) sind Personen (persons), Institutionen/Organisationen (organisations), Orte (places) und Ereignisse (events). Herzstück der Datenbank ist das ‚Datenerfassungsmodell‘ für die Analyseeinheiten (entity-relationship-model). Dieses basiert auf zwei ‚Pfeilern‘: der Auszeichnung von Textpassagen (in den im XML-Format vorliegenden Quellentexten) und dem Anlegen von zentralen Registern der Analyseeinheiten (indicies). Die Verknüpfung beider Bereiche geschieht mit Hilfe von Graphen (IDs und Verweise auf IDs). Das Modell strukturiert für die Analyseeinheiten neben der Art ihrer Auszeichnung im Text (Quelle) und ihrer Anlage im Register, auch die Möglichkeiten der inhaltlichen Erfassung in Bezug auf ihr Auftauchen in Ereignissen und ihren Funktionen in Rechtsgeschäften sowie die Ausstattung mit Attributen und relationalen Verbindungen.
Die mit Informationen zu verschiedensten Entitäten ausgestatteten Textpassagen (strings) werden in den Digital Humanities factoids genannt.6 Die Modellierung der Datenbank orientiert sich deshalb am Modell der factoid prosopography.7 Die Aufbereitung der Daten, die Anlage der Register und die Auszeichnung der Textsegmente erfolgen in XML mit Hilfe des XML-Editors Oxygen und basieren, wie bereits erwähnt, auf den Richtlinien der TEI. Zur Auswertung von in diesem Erfassungsschema ausgezeichneten (getaggten)8 Quellenbeständen wurden python-Programmierungen für jupyter-notebook erstellt. Das Datenmodell, wie auch die erfassten Regesten und Satzbucheinträge des Jahres 1448, sind in folgendem git repository einsehbar: https://github.com/KGruenwald/db_for_medieval_legal_transactions_documentation.
3. Das entity-relationship-model
Abbildung 1 zeigt die theoretische Ebene des entity-relationship-model. Informationen, welche in die Register aufgenommen werden, befinden sich innerhalb der mit list of … gekennzeichneten grauen Kästchen. Alle anderen Informationen werden direkt im digital aufbereiteten Quellentext ausgezeichnet.

Abbildung 1: JPG des theoretischen Bereichs der Graphen-Datei model_of_entities_db_legtrans_fullversion_by_KG.graphml. Graue Kästchen = Register (list of entities); Blau = Entitäten; grün = Rolle/Funktion im RG; violett = Relationen; orange = Attribute; blaugrau = zusätzliche Auszeichungsoptionen; weiß = Informationen sind im TEI-Header enthalten.
In Abbildung 2 ist nun die technische Ebene der XML-Mark-Ups am Beispiel der Art (kind) des Rechtsgeschäfts (events) dargestellt. Das linke Fenster zeigt die Art der Auszeichnung (des Taggs): im Beispiel mit dem Mark-Up <catchwords n=disp>, um die für die Kategorisierung des Rechtsgeschäfts notwendigen dispositiven Verben zu markieren.
Da das entity-relationship-model als Graphen-Datei (graphml) konzipiert ist, kann für jedes Element im Modell das entsprechende Mark-Up angezeigt werden.

Abbildung 2: Screenshot des praktischen Bereichs der Graphen-Datei model_of_entities_db_legtrans_fullversion_by_KG.graphml. Das Linke Fenster zeigt die Art des Taggs am Beispiel Art des events (kind) mit dem Mark-Up .
4. Die vier Auszeichungsebenen im Text
Im Zuge der Auszeichnung eines Quellentextes (tagging) wird das Modell quasi einmal von oben nach unten durch dekliniert. Die hierarchische Struktur der Auszeichnungsebenen gewährleistet die systematische Verbindung der Ebenen (alle factoids der nachgelagerten Ebenen sind Teil der höher gelagerten Ebenen).
Die erste Auszeichnungsebene betrifft die events, da Informationen zur Quelle bereits im TEI-Header gespeichert sind.
Die Kategorisierung dieser Auszeichnugsebene wird nicht sofort durch vorgegebene Kategorien vorgenommen, sondern die für diese zentralen Textpassagen (strings) der dispositiven Verben mittels der Notation catchwords extrahiert und erst im Nachhinein systematisch Kategorien entwickelt und kategorisiert.
Diese nachträgliche Kategorisierung ermöglicht es flexibel auf die verschiedenen Rechtsgeschäfte in den unterschiedlichen Quellenbeständen zu reagieren. So wurden im event des Regests Nr. 3269 zum Beispiel folgende Passagen gekennzeichnet: „beurkundet, dass vor ihm in der Bürgerschranne” „geklagt habe” „spricht“ „zu“.9 Über die Extraktion kann nun systematisch für diese Art von events folgende hierarchisierte Kategorisierung vorgenommen werden: ‘Gerichtsurteil_Bürgerschranne_Zuspruch’.10 Bei herkömmlicher Vorgehensweise wäre wohl ‘nur’ ‘Gerichtsurteil’ als Kategorie angelegt worden und eine nachträgliche Ausweitung der Sub-Kategorisierungen hätte ein erneutes Durchforsten der Quellen benötigt.
Die zweite Auszeichnungsebene erfasst die Funktionen im event respektive Rechtsgeschäft (im Modell grün). Folgende Funktionen/Rollen im Rechtsgeschäft können ausgezeichnet werden:
- Austeller/in respektive Geber/in (issuer)
- Empfänger/in (recipient)
- Zeuge/in respektive Siegler/in (witness)
- Transaktionsgüter (transactiongood_I + II + III): transactiongood_I ‚wandert‘ immer von Aussteller zu Empfänger; transactiongood_II immer von Empfänger zu Aussteller; bei transactiongood_III handelt es sich um ein Streitobjekt (meist vor Gericht);
- weitere Funktionen (other): hiermit können weitere Rollen im Rechtsgeschäft beschrieben werden, wobei die Beschreibung der Art dieser Funktion ebenfalls mit Hilfe der catchwords geschieht, indem nun die Textpassage zur Rolle im Rechtsgeschäft ausgezeichnet wird. Mit other werden vor allem Grundherren und -frauen sowie assoziierte Personen (z.B. Ratgeber/innen, Intervenient/innen) und Institutionen ausgezeichnet. So können Informationen zu sämtlichen Akteuren, die in die erfassten Rechtsgeschäfte involviert waren, markiert werden. Als Platzhalter steht in Abbildung 2 die häufige Formulierung für am Rechtsgeschäft beteiligten Grundherren/-frauen ‚mit Handen‘.11
In der dritten Auszeichnungsebene werden nun die Textpassagen, welche Informationen zu den Analyseeinheiten der Personen, Orte und Organisationen aufweisen, mittels reference strings (rs) markiert und durch das TEI-Attribut ref mit einem Graphen (ID) ausgestattet, welcher auf den entsprechenden Registereintrag verweist. Der XML-Editor Oxygen ermöglicht es, während des Auszeichungsvorgangs (mark-up), die in den Registern (list of … – indices) enthaltenen IDs per drop-down zu durchsuchen, dabei normierte Schreibweisen und Anmerkungen zu den in den indices angelegten IDs direkt anzuzeigen und so die schnelle Suche und Identifizierung der Analyseeinheiten (Entitäten) zu unterstützen.
Die vierte Auszeichnungsebene enthält nun Attribute und relationale Verbindungen. Beide werden mit Hilfe des TEI-Elements roleName markiert und über das TEI-Attribut type mit einer Kategorie versehen. Im Falle von Attributen kann es sich um Berufe (prof), Titel (title) und/oder Todesfloskeln (dead), wie z.B. „selig“, handeln. Bei relationalen Verknüpfungen können verwandtschaftliche (kin), geschäftliche (buis = buisness), repräsentative (rep = legal representation), besitzrechtliche (owner),12 amtliche (office), titulare (title_ref), topographische (topo) und dienstliche (staff) Verbindungen aufgenommen und durch das TEI-Attribut corresp mit einem Graphen ausgestattet, welcher auf die – über die markierte Textpassage verknüpfte – Entität verweist. Darüber hinaus isr es möglich über das TEI-Attribut select zusätzliche Präzisierungen vorzunehmen, um z.B. bei der Bezeichnung ‚hofmaister ze Dornpach‘ sowohl das Amt des Hofmeisters mit corresp auf den Herzog (von Österreich) verbinden, als auch über select die räumliche Einschränkung mittels Verweis auf den Registereintrag des Ortes (ID = ‘pl__dornbach’) vornehmen zu können.13 Die Qualität der Beziehungen der in jedem Regest auftretenden relationalen Bezüge zwischen den ausgezeichneten Akteuren (Personen, Organisationen, Orte) können so erfasst und nachträglich sortiert und kategorisiert werden. Die Normierung der ausgezeichneten roleNames geschieht über eine entsprechende Normierungstabelle, welche alle bis dato markierten Textpassagen/Schreibweisen sowie deren mögliche Kategorisierung enthält.14 Die Normierung der Schreibweisen in der Auswertung geschieht automatisiert.
Für alle Auszeichnugssebenen ist es grundsätzlich möglich, sowohl durch setzen des TEI-Attributs cert einen Tagg mit einer Einschätzung der Wahrscheinlichkeit der Richtigkeit (possibility) der ‚interpretierten‘ Aussage des factoids zu versehen (high—low), als auch Passagen als unklar (unclear) oder von den Bearbeiter/innen hinzugefügt (add) zu kennzeichnen.
5. Die Register (indices – list of …)
Die Register (list of … – indices) dienen zur zentralen Identifizierung der Entitäten mittels IDs, zur Normierung von Namen (forename, surename, addname) und zur Ergänzung weiterer außertextlicher Informationen (z.B. sex, GIS-Koordinaten, Adressen von Institutionen).
Ebenso so ist es möglich das Namenskürzel des/der Bearbeiters/in zu ergänzen.
Die Art der Konstruktion der IDs ist wegen der erwähnten ID-Durchsuchungsoption des XML-Editors Oxygen zentral, da sicher gestellt werden muss, dass die Analyseeinheiten über die IDs gefunden werden können. Aus diesem Grund wird im Folgenden ausführlich auf die Konstruktion der IDs eingegangen. Die Register (indices) sind für die Entitäten der Ereignisse (events), Personen (persons), Organisationen (organisations) und Orte (places) angelegt.
5.1 Liste der events (eventList):
Das Register der events enthält Angaben zu:
- Datum (@when, @form @to, @notAfter)
- Kategorie (label)
- Bearbeiter/in (@resp)
Die ID-Erstellung für Ereignisse erfolgt nach dem folgenden Schema:
Zur Konstruktion der IDs der events wird auf die Nummer der Quelle im Quellenbestand zurückgegriffen, wodurch jeder event mit der ihn erwähnenden Quelle verknüpft ist.15
Event–IDs bestehen aktuell aus drei Teilen:
ev__ + Quellenkürzel des Quellenbestandes + (_) Nummer der Quelle im Quellenbestand
ev__ = zeigt an, dass es sich bei der ID um einen event handelt
Quellenkürzel des Quellenbestandes = normiertes Quellenkürzel des Qullenbestandes
(z.B. QGW_II_II_)
Nummer der Quelle im Quellenbestand = Nummer der Quelle im Quellenbestand
(z.B. _2870)
BSP: ev__QGW_II_II_2870 ev__SB_CD_00642
Der Eintrag in der eventList gestaltet sich dann folgendermaßen (statt dem Attribut when können auch die Attribute und from…to und notAfter verwendet werden):
<event when=“1449-08-04“ xml:id=“ev__SB_CD_00642„>
<label>Burgrecht</label>
</event>
Die Kategorisierung des events wurde über die extrahierten catchwords „habent verkaufft“und „gelts purkrechtz“ gebildet.16
Bei erwähnten Rechtsgeschäften (mentioned events) wird ein ‚_men_ + *FORTLAUFENDE NUMMER*‘ an die ID des events angefügt.
BSP: ev__QGW_II_II_00606_men_1
5.2 Liste der persons (personList):
Das Register der persons enthält Angaben zu:
- Geschlecht (@sex)
- Vornamen (forename)
- Nachnamen (surname)
- Namenszusätze (addName)
- genealogische Namenszusätze (genName)
Zusätzlich gibt es die Möglichkeit Anmerkungen (notes) zu setzen. Da alle Informationen mit Ausnahme des Geschlechts textbezogen extrahiert werden, dienen diese nicht zur Anreicherung von verarbeitbaren Informationen, sondern zur Anlage von Informationen, welche die Identifizierung von Personen mit Hilfe der dropdown-Vorschau beim Durchsuchen der IDs erleichtern.
Die Auszeichnungsoptionen orig und reg zeigen an, ob es sich um originale oder regularisierte Schreibweisen handelt. Im letzteren Fall sollte auf eine Quelle (source) – in der Regel handelt es sich hierbei um ein Register – verwiesen werden. Dieses Prinzip gilt grundsätzlich für die Normierung von Namen.
Schreibweisen von Vornamen werden über eine Vornamennormierungstabelle, welche alle bisher gesammelten Schreibweisen enthält, vereinheitlicht17 und Nachnamen über Register (weiterer) Quelleneditionen normiert und mit diesen verknüpft.
Vorgehensweise beim markieren/taggen von Personen:
- Suche über drop down (Vorsicht: Normierte Vornamen verwenden; auf Klangähnlichkeiten achten: d/t, ch/k; b/p; ai/ei/ay/ey; e/a; b/w)
- Person befindet sich noch nicht im zentralen Personen-Register (personList): Konsultation des Registers des Quellenbestandes (für jedes Register das Vorwort beachten; im Zweifelsfall Vor- UND Nachnamen-Suche)
- Neuanlage der Person in der personList (zentrales Register)
Anlage von Personen in der personList
Erstellen eines leeren person-taggs (<person/>):
<person></person>
Ergänzung um das Geschlecht (sex) der Person:
<person sex="m"></person>
Ergänzung des konsultierten Registers:
<person sex="m" source="QGW_II_II_register_pg_486"></person>
Ergänzung der ID:
<person sex="m" source="QGW_II_II_register_pg_486" xml:id="pe__johann_maurperger_QGW_II_II_2870"></person>
Die ID-Erstellung für Personen erfolgt nach dem folgenden Schema:
Person-IDs bestehen aus vier oder fünf Teilen:
pe__ + Vorname + (_) Nachname (wenn vorhanden) + (_) Quellenkürzel des Quellenbestandes + (_) Nummer der Quelle im Quellenbestand
pe__ = zeigt an, dass es sich bei der ID um eine Person handelt
Vorname = wird mit Hilfe der Vornamen_Normierung (https://docs.google.com/spreadsheets/d/1a91QkqzNyPZ1OGXvx3IIyaT4VAQMoYG0ZX0dQLUUHaU/edit#gid=0) normiert
Nachname = wird über das Register des Quellenbestandes normiert (für die Wiener Beispiele: Register der QGW_II_*I-III*_ oder SB_CD_); falls nicht vorhanden/gefunden wird die Originalschreibweise übernommen; falls kein Nachname vorhanden, wird die Berufsbezeichnung als Nachname verwenden (ohne _der_)
Quellenkürzel des Quellenbestandes = normiertes Quellenkürzel des Qullenbestandes
(z.B. QGW_II_II_)
Nummer der Quelle im Quellenbestand = Nummer der Quelle im Quellenbestand
(z.B. _1109)
BSP: pe__johann_maurperger_QGW_II_II_2870
WICHTIG: in der ID keine Umlaute verwenden!
Fortlaufende Nummerierung nach Alphabet = bei Vorkommen von zwei Personen gleichen Namens in ein und derselben Quelle
BSP: pe__agnes_QGW_II_II_3250_a pe__agnes_QGW_II_II_3250_b
Ergänzung der/des Bearbeiters/in (resp):
<person sex="m" source="QGW_II_II_register_pg_486" xml:id="pe__johann_maurperger_QGW_II_II_2870" resp="kg"></person>
Ergänzung des Vornamens (forename):
<person sex="m" source="QGW_II_II_register_pg_486" xml:id="pe__johann_maurperger_QGW_II_II_2870" resp="kg">
<persName>
<forename>
<reg>Johann</reg>
</forename>
</persName>
</person>
Ergänzung des Nachnamens (surname):
<person sex="m" source="QGW_II_II_register_pg_486" xml:id="pe__johann_maurperger_QGW_II_II_2870" resp="kg"></person>
<persName>
<forename>
<reg>Johann</reg>
</forename>
<surname>
<reg>Maurperger</reg>
</surname>
</persName>
</person>
Ergänzung des Nachnamens (nur Nachname im konsultierten Register gefunden):
‚Stephan Fügenstaler‘
<person sex="m" xml:id="pe__stephan_fuegenstaler_SB_CD_00349" resp="kg">
<persName>
<forename>
<reg>Stephan</reg>
</forename>
<surname>
<reg source="QGW_II_I_register_pg_515">Fügenstaler</reg>
</surname>
</persName>
</person>
Ergänzung des Nachnamens (keinen entsprechenden Nachname im konsultierten Register gefunden): ‚Niklas Legler‘
<person sex="m" xml:id="pe__niklas_legler_SB_CD_00406" resp="kg">
<persName>
<forename>
<reg>Niklas</reg>
</forename>
<surname>
<reg>Legler</reg>
<orig>Lègler</orig>
</surname>
</persName>
</person>
Ergänzung des Nachnamens von Frauen oder Kindern:18
Bei Frauen und Kindern ist die Ergänzung des ‚potentiellen‘ Nachnamens von zentraler Bedeutung, da so die Identifikation der Personen erheblich verbessert wird. Gerade Frauen können auf diese Weise eine ganze Reihe an Nachnamen sammeln.
BSP 1: ‚Katharina Swarczin“
<person sex="f" xml:id="pe__katharina_SB_CD_00640" resp="kg">
<persName>
<forename>
<reg>Katharina</reg>
</forename>
<surname>
<add><reg source="QGW_II_II_register_pg_511">Swarczin</reg></add>
</surname>
<addName></addName>
</persName>
<note>Gem. Peter Swarcz</note>
</person>
BSP 2: ‚Johann Swarcz‘
<person sex="m" xml:id="pe__johann_swarcz_SB_CD_00640" resp="kg">
<persName>
<forename>
<reg>Johann</reg>
</forename>
<surname>
<add><reg source="QGW_II_II_register_pg_511">Swarcz</reg></add>
</surname>
<addName></addName>
</persName>
<note>Sohn v. Katharina u. Peter Swarcz</note>
</person>
Ergänzung von Namenszusätzen (addName):
<person sex="m" source="QGW_II_II_register_pg_486" xml:id="pe__johann_maurperger_QGW_II_II_2870" resp="kg"></person>
<persName>
<forename>
<reg>Johann</reg>
</forename>
<surname>
<reg>Maurperger</reg>
</surname>
<addName>
<reg>der Münzer</reg>
</addName>
</persName>
</person>
Ergänzung der genealogischen Zählung (genName):
<person sex="m" source="QGW_II_I_register_pg_496"
xml:id="pe__stephan_poll_QGW_II_I_1101" resp="kg">
<persName>
<forename>
<reg>Stephan</reg>
</forename>
<surname>
<reg>Poll</reg>
</surname>
<addName>
<reg/>
</addName>
<genName>III</genName>
</persName>
<note>Wiener Bürger, Gem. Anna</note>
</person>
Ergänzung von Anmerkungen (note):
<person sex="f" xml:id="pe__katharina_SB_CD_00640" resp="kg">
<persName>
<forename>
<reg>Katharina</reg>
</forename>
<surname>
<add>
<reg source="QGW_II_II_register_pg_511">Swarczin</reg>
</add>
</surname>
<addName></addName>
</persName>
<note>Gem. Peter Swarcz</note>
</person>
Zusätzlich wurde eine Programmierung entwickelt, welche die erstmalige Todesnennung erkennt und somit ein laufend aktualisiertes frühest mögliches Todesdatum’ (earliest possible death) ergänzt: ‚Michael Füchsel‘
<person sex="m" source="QGW_II_I_register_pg_515; QGW_II_II_register_pg_457"
xml:id="pe__michael_fuechsel_QGW_II_I_1108" resp="kg">
<persName>
<forename>
<reg>Michael</reg>
</forename>
<surname>
<reg>Füchsel</reg>
</surname>
<addName/>
</persName>
<note/>
<death notAfter="1448-06-26">1448-06-26</death>
</person>
5.3 Liste der organisations (orgList):
Das Register der organisations enthält Angaben zu:
- Name (original/regularisiert)
- Art der Organisation: Dioezese_Erzdioezese, Kirche_Kapelle, Spital_Siechenhaus, Kloster_f, Kloster_m, Pfarre, Altar, Messe, Zeche_Bruderschaft, Stadt, Gemeinde, Reich, Königreich, Herzogtum, OTHER (z.B. Vatikan)
- Observanzen bei Klöstern (z.B. OSB = Ordo Sancti Benedicti )
- Adresse (adress – adressLine)
- Links (idno)
Die ID-Erstellung für Organisationen erfolgt nach dem folgenden Schema:
Organisation-IDs bestehen aus 2+n Bestandteilen:
org__ + Siedlung
org__ + Siedlung + (-) Patrozinium (mit st_) und/oder Eigenname + (_) Institutionelle Form der Organisation (wenn vorhanden) + (-) Art der Unterorganisation (_) Patrozinium (mit st_) und/oder Eigenname + (-) …
org__ = zeigt an, dass es sich bei der ID um eine Organisation handelt
Siedlung = Ort der Organisation
Patrozinium = wird mit der Vorsilbe st_ und der Name der/des Heilgen mit Hilfe der Vornamen_Normierung normiert (Vorsicht: „unser frawen“ o.Ä. = st_maria)
Eigenname = wird über das Register des Quellenbestandes normiert; falls nicht vorhanden/gefunden werden weitere Register hinzugezogen; im Notfall wird die Originalschreibweise übernommen;
Art der Unterorganisation = als mögliche Arten der Unterorganisationen kommen Pfarren, Kapellen, Siechenhäuser/Spitäler, Alter und Messen vor
Benennung der Messe/Zeche = Stifter/in der Messe oder Bezeichnung der Zeche/Bruderschaft
Beispiele (Grundsätzlich gilt: vom Allgemeinen ins Besondere!)
Städte/Orte: org__wien org__krems
Diözese: org__salzburg-erzdioezese org__passau-dioezese
Kirchen/Kapellen: org__wien-st_stephan org__wien-st_maria_im_rathaus org__krems-st_katharina_kapelle
Kirchen/Kapellen (Pfarren): org__achau-pfarre org__wien-st_peter_pfarre19
Spitäler/Siechenhäuser: org__wien-st_johannes_siechenhaus org__wien-buergerspital20
Klöster: org__heiligenkreuz-zisterzienser org__wien-st_niklas_vor_dem_stubentor_zisterzienserinnen21
Kapellen (in Kirchen): org__wien-st_stephan-kapelle_st_katharina
Altäre: org__wien-st_stephan-altar_st_dorothea
Messen: org__wien-st_stephan-altar_st_martin-messe_chranvogel22
Zechen/Bruderschaften: org__wien-st_stephan-zeche_st_markus_kaufleute org__wien-st_maria_magdalena-zeche_schreiber
Anlage von Organisationen in der orgList:
BSP: Stadt
<org type="Stadt" xml:id="org__wien" resp="kg">
<orgName>
<reg>Wien</reg>
</orgName>
<note>Bürgermeister, Rat (und Gemein)</note>
<location>
<address>
<addrLine corresp="pl__wien"></addrLine>
</address>
</location>
</org>
BSP: Kloster
<org type="Kloster_f" xml:id="org__wien-st_niklas_vor_dem_stubentor_zisterzienserinnen" resp="kg">
<trait>
<label>Observance</label>
<desc>OCist</desc>
</trait>
<orgName>
<reg source="QGW_II_I_register_pg_558">St. Niklas-vor dem Stubentor</reg>
</orgName>
<idno type="URI">https://www.geschichtewiki.Wien (W).gv.at/Nikolaikloster_(3)</idno>
<location>
<address>
<addrLine corresp="pl__wien-st_niklas_vor_dem_stubentor"></addrLine>
</address>
</location>
</org>
Die Unterorganisationen werden hierarchisch innerhalb der Überorganisationen eingeordnet. Im Beispiel eine Kirche mit Altar und Messen.
<org type="Kirche_Kapelle" xml:id="org__wien-st_stephan" resp="kg">
<orgName><reg source="QGW_II_II_register_pg_506-509">St. Stephan</reg></orgName>
<idno type="URI">https://www.geschichtewiki.Wien (W).gv.at/Stephansdom</idno>
<address>
<addrLine corresp="pl__wien-st_stephan"></addrLine>
</address>
<org type="Altar" xml:id="org__wien-st_stephan-altar_st_ulrich">
<orgName><reg source="QGW_II_II_register_pg_578">Ulrichsaltar</reg></orgName>
<org type="Messe" xml:id="org__wien-st_stephan-altar_st_ulrich-messe_fuechsel">
<orgName><reg source="QGW_II_II_register_pg_507">Füchselmesse</reg></orgName>
</org>
<org type="Messe" xml:id="org__wien-st_stephan-altar_st_ulrich-messe_graf">
<orgName><reg source="QGW_II_II_register_pg_578">Grafenmesse</reg></orgName>
</org>
</org>
</org>
5.4 Liste der places (placeList):
Das Register der places enthält Angaben zu:
- Name (original/regularisiert)
- Art des places (@type = settlement, street, immo)23
- Observanzen (bei Klöstern)
- Adresse (bei Liegenschaften)
- Koordinaten (Längen- und Breitengrade)
- Links (z.B. geonames.org)
Die ID-Erstellung für Orte erfolgt nach dem folgenden Schema:
Place-IDs bestehen aus zwei, drei oder vier Teilen:
pl__ + Siedlung
pl__ + Siedlung + (-) Name der Straße/des Platzes/der Institution
Städte/Orte (settlement): pl__wien
Kirchen (street): pl__wien-st_stephan pl__wien-st_pankraz
Plätze (street): pl__wien-hoher_markt pl__wien-hoher_markt_fischmarkt pl__wien-neuer_platz
Straßen (street): org__wien-strauchgasse org__wien-tiefer_graben
Bei Immobilien/Liegenschaften wird die ID etwas anders gebildet. Dies liegt daran, dass Liegenschaften (v.a. Häuser) meist nur über die Erwähnungen im Zusammenhang mit Straßen gezählt werden aber nicht geographisch durchnummeriert werden können.
pl__ + Siedlung + (-) immo (bei Liegenschaften) + (_) Name des Platzes/der Straße + (_) Nummer der Liegenschaft im bisherigen Liegenschaftsbestand der DB
pl__ = zeigt an, dass es sich bei der ID um einen Ort handelt
Siedlung = Ort der Organisation
immo_ = zeigt an, dass es sich um eine Liegenschaft (Immobilie) handelt
Name des Platzes/der Straße = wird über das Register des Quellenbestandes normiert; falls nicht vorhanden/gefunden werden weitere Register hinzugezogen; im Notfall wird die Originalschreibweise übernommen;
Nummer = fortlaufende Nummerierung der Liegenschaft im bisherigen Liegenschaftsbestand der DB
BSP: pl__wien-immo_karntnerstrasse_1 pl__wien-immo_alserstrasse_vor_schottentor_2
Anlage in der placeList:
BSP: Siedlung
<place xml:id="pl__wien" type="settlement" resp=“kg“>
<placeName>Wien</placeName>
<location>
<geo decls="LatLng">48.20849 16.37208</geo>
</location>
<idno type="URL">https://www.geonames.org/2761369/vienna.html</idno>
</place>
BSP: Kirche
<place xml:id="pl__wien-st_stephan" type=“street“ resp=“kg“>
<placeName>
<reg source="QGW_II_II_register_pg_507">S. Stephan (Allerheiligen Pfarr- und
Domkirche, I. Bezirk)</reg>
</placeName>
<location>
<geo decls="LatLng">48.20847 16.37265</geo>
<address>
<addrLine></addrLine>
</address>
</location>
<idno type="URI">https://www.geonames.org/6324757/stephansdom.html</idno>
</place>
BSP Straße
<place xml:id="pl__wien-strauchgasse" type="street" resp=“kg“>
<placeName>
<reg source="QGW_II_II_register_pg_510">Strauchgasse (I.Bezirk)</reg>
</placeName>
</place>
BSP Platz (bei Märkten und Plätzen ist, wie bei den Organisationen eine Hierarchisierung möglich)
<place xml:id="pl__wien-hoher_markt" type="street" resp=“kg“>
<placeName>
<reg source="QGW_II_I_register_pg_529">Hohermarkt (I.Bezirk)</reg>
<orig>forum</orig>
<orig>altum forum</orig>
</placeName>
<place xml:id="pl__wien-hoher_markt_fischmarkt" resp=“kg“>
<placeName><reg source="QGW_II_I_register_pg_512">Fischmarkt, an dem
hohenmarkt</reg></placeName>
</place>
<place xml:id="pl__hoher_markt_wentkremen" resp=“kg“>
<placeName><reg source="QGW_II_II_register_pg_515">unter den Wentkremen, an dem
hohenmarkt</reg></placeName>
</place>
</place>
BSP Liegenschaft/Immobilie
<place xml:id="pl__wien-immo_pippingerstrasse_1" type=“immo“ resp=“kg“>
<placeName><reg>Johann und Agnes Hinlauf Haus</reg></placeName>
<location>
<address>
<addrLine corresp="pl__pippingerstrasse"/>
</address>
</location>
</place>
Die Übergänge zwischen Immobilen/Liegenschaften und Straßen/Plätzen ist oft fließend. Im Zweifelsfall entscheidet der/dieBearbeiter/in. Als Grundlage sollte gelten: werden Liegenschaften als zentrale topographische Referenzpunkte in den Quellen genannt, so ist die Anlage als Straße/Platz sinnvoll (zu Rate gezogen können hierbei wiederum Quellenregister; für Wien u.a. die Register der QGW).
BSP: ‚der Krafthof‘
<place xml:id="pl__wien-krafthof">
<placeName>
<reg source="QGW_II_III_register_pg_561">Krafthof</reg>
</placeName>
</place>
6. Der Auszeichnungsvorgang im Text – das Taggen
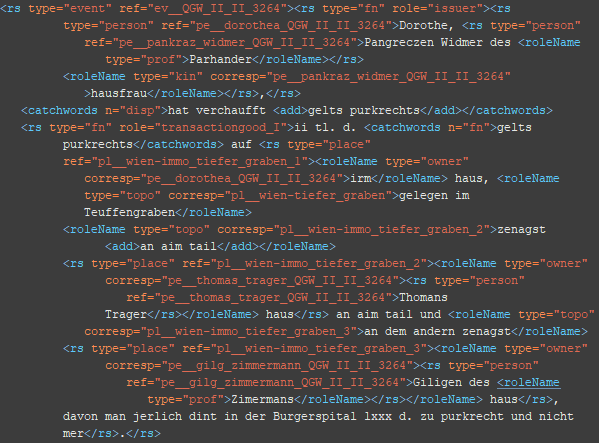
Der Folgende Abschnitt beschriebt den Auszeichnungsvorgang (das Taggen) anhand eines ‚Burgrechtskredits‘,24 welchen Dorothea ‚Widmerin’ am 5. August 1448 aufgenommen hat. Über dieses Rechtsgeschäft ist uns sowohl der Grundbucheintrag als auch die Urkunde überliefert. Anhand dieser beiden Quellen – im Falle der Urkunde das Regest derselben – wird der Tagg-Vorgang durchgespielt.
1. Schritt: Einfügen des Kürzels des Bearbeiters/der Bearbeiterin (@resp)
![]()
2. Schritt: Auszeichnung der Rechtsgeschäfte (events)
< rs type=“event“ ref=“ev__*“>
BSP 1 (Bild und Regest der Urkunde unter: https://www.monasterium.net/mom/AT-WStLA/HAUrk/3264/charter?q=3264)
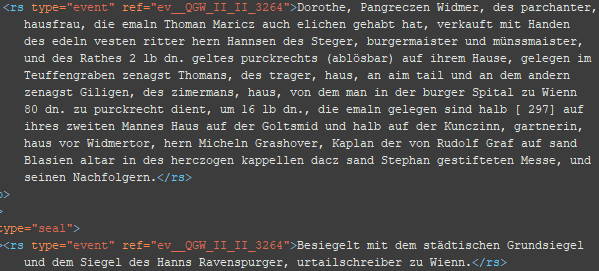
BSP 2 (Bild und Regest der Urkunde unter: https://grundbuecher.acdh.oeaw.ac.at/pages/show.html?document=e00300_1448-08-05.xml&directory=editions)
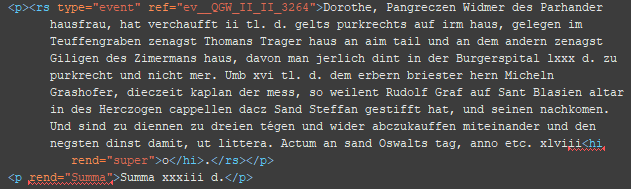
3. Schritt: Auszeichnung des dispositiven Verbs (‚Prädikatsverbum‘)
<catchwords n=“disp“/>
BSP 1

BSP 2

Im Beispiel beschriebt die Formulierung „gelts purkrechts“ nicht nur die Art des Verkaufs, sondern ebenfalls die Art des Transaktionsguts, weshalb dieses hier ‚doppelt‘ getaggt werden sollte. Dafür ist die Ergänzung mit dem Attribut add notwendig, da jede Information – auch wenn sie implizit im Text vorhanden ist – einen Textausschnitt benötigt sind manchmal Ergänzungen in einzelnen Tags notwendig.25 Diese lassen sich mithilfe von einem <add> als ‚Aufhänger‘ für diese impliziten Informationen einfügen: <add/>.
BSP 1

BSP 2

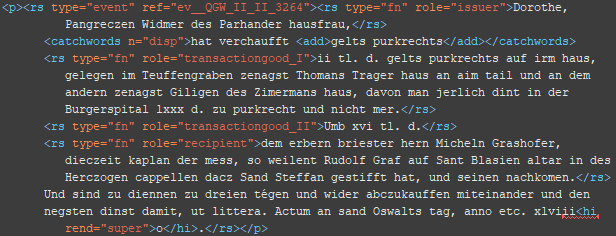
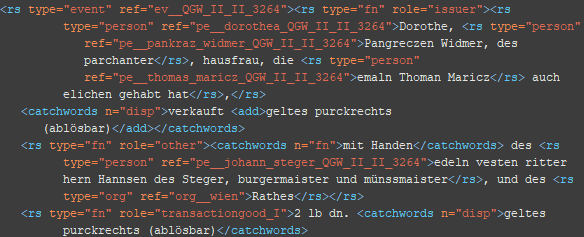
4. Schritt Zuordnung der Funktionen im Rechtsgeschäft (soweit vorhanden)
<rs type=“fn“ role=“*“/> @role: issuer, recipient, witness, other (Personen, die z.B. als Ratgeber oder – wie in diesem Fall – als Grundherren einem Rechtsgeschäft zustimmen müssen)
BSP 1
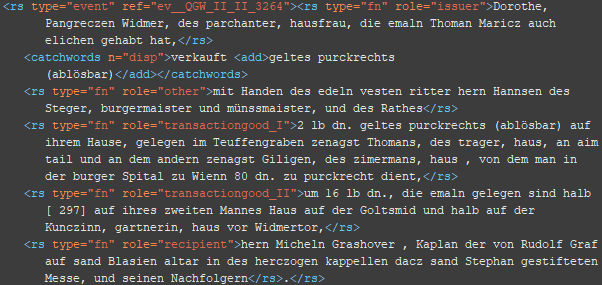
BSP 2

(4. b) Bei <rs type=“fn“ role=“other“> muss die Formulierung mit <catchwords n=“fn“/> getaggt werden, um die die funktionale Rolle der im Rechtsgeschäft als ‚other‘ ausgezeichneten Personen zu spezifizieren.
BSP 1

Dies ist ebenfalls möglich bei Transaktionsgütern oder Empfängern, wenn deren Rolle/Funktion im Rechtsgeschäft genauer beschrieben werden soll.
BSP 1

BSP 2

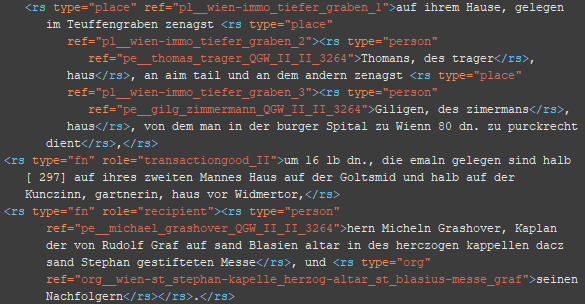
5 a. Schritt: Auszeichnung der Analyseeinheiten (entities)
zunächst nur <rs/> (wg. Überblick)
BSP 1
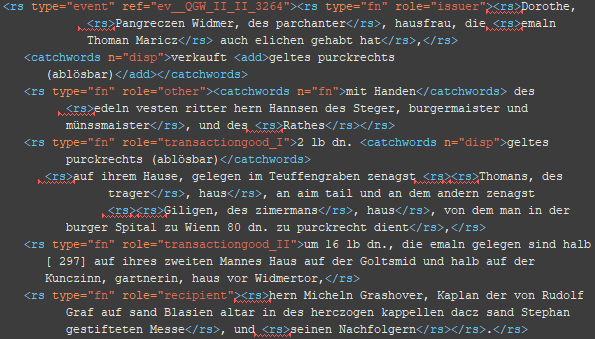

BSP 2
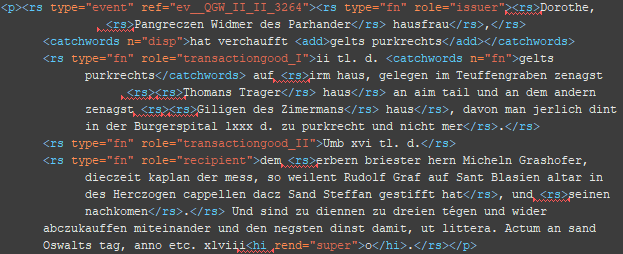
5 b. Schritt: Zuordnung der Analyseeinheiten im rs-Taggs.
Das ref-Attribut enthält die eindeutige ID der jeweiligen Entität.
<rs type=“*“ ref=“*__*“> @type: person, org, place
BSP 1

BSP 2
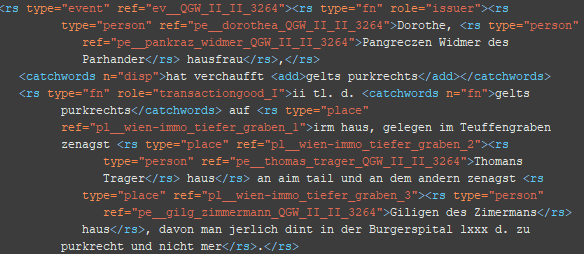
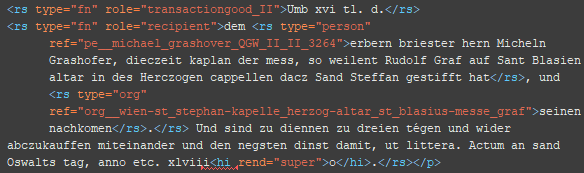
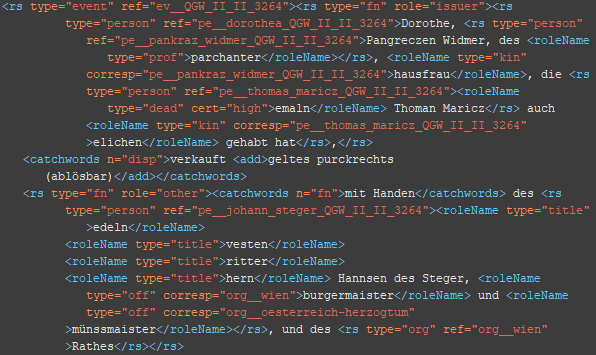
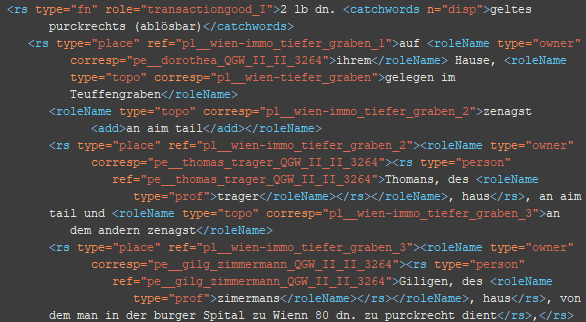
6. Schritt: Ergänzung der Attribute und Relationen (roleNames)
<roleName type=“*“> @type: prof, title (Attribute)
<roleName type=“*“ corresp=“*__*“> @type: title_ref, rep, off, staff, friend, buis, kin, owner, topo (Relationen)
Die relationalen roleNames benötigen – im Gegensatz zu den roleName-Typen Beruf und Titel – ein corresp-Attribut, da sie eine Verbindung zu einer weiteren Entität angeben.
BSP 1
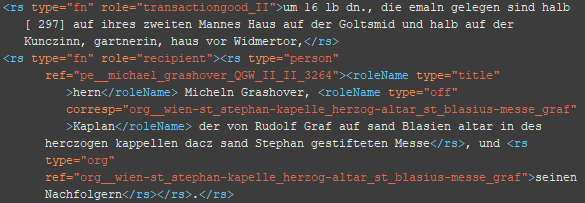

BSP 2
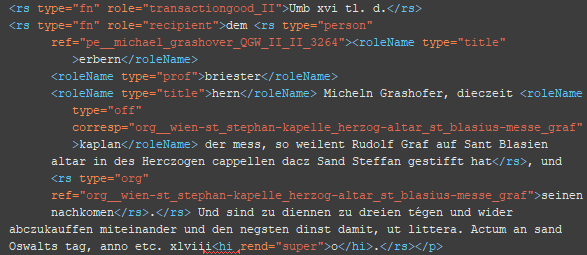
Im Falle von erwähnten Rechtsgeschäften (mentioned events), kann genauso vorgegangen werden wie bei den ‚Haupt‘-events. Als ID kann je nach Interesse des/der Bearbeiters/in entweder ‚NULL‘ (um nur anzugeben hier gibt es noch mentioned events BSP 1) oder die oben erwähnte Option durch das Anfügen von ‚_men_*FORTLAUFENDE NUMMER*‘ an die ID des events (BSP 2).
BSP 1:


![]()
BSP 2:
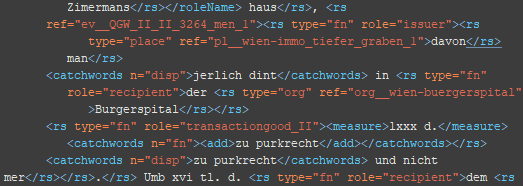
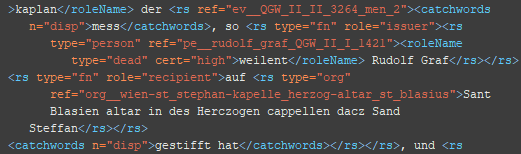
7. Schritt:Auszeichnung von Maßeinheiten
Bist dato werden Maßeinheiten nur durch <measure/> als solche gekennzeichnet. Für die weitere Verarbeitung ist es sicherlich sinnvoll sich bereits entwickelter Ontologien zu bedienen.
BSP 2
![]()
![]()
7. Auswertungsoptionen
Die Aufgliederung in Analyseeinheiten (Entitäten), Funktionen (rechtsgeschäftsrelevante Ebene) und – relationalen – Attributen (Merkmale und relationale Verbindungen) ermöglicht es bei Auswertungen einzelne Datensets nach diesen Ebenen zu strukturieren.
Die hier vorgestellten Auswertungsoptionen wurden im Zuge der Dissertation und von meinem Kooperationspartner Jan Bigalke für das Projekts ‚Stadt und Gemeinschaft‘ programmiert. Diese Programmierungen zur Auswertung der Datenbank wurden mittels der Programmiersprache python in jupyter-notebook erstellt.
Die erfassten Daten lassen sich in verschiedene Dateiformate konvertieren, um weiterführende, quantifizierende sowie qualitative Auswertungen in unterschiedlichen Softwareprogrammen zu ermöglichen. Die aktuelle Programmierung ermöglicht es Tabellen (csv) zu Personen, Orten und Organisationen ihrer gesammelten Merkmale (Attribute), Rollen im Rechtsgeschäftund Relationen auszuwerfen.
Übersicht über erfasste Informationen anhand der Erfassung des Jahres 1448
Insgesamt wurden für das Jahr 1448 75 Satzbucheinträge und 42 Regesten der Quellen zur Geschichte der Stadt Wien (QGW), d.h. in Summe 117 Quellen erfasst. In diesen befanden sich Informationen zu 168 Rechtsgeschäften (events).
Abbildung 3 zeigt einen Screenshot der Übersichtstabelle zu allen Personen. Diese zeigt die ID der Person, deren Name, die Zahl der Nennungen, das Geschlecht, die Quellen und die Jahre der Nennungen und ist nach der Häufigkeit der Nennungen (Spalte: ‚number‘) sortiert. Die gelegentliche Wiederholung von Nachnamen ergibt sich daraus, dass hier teilweise die von dem/der Bearbeiter/in regularisierte und die zugrundeliegende originale Schreibweise in der personList enthalten ist (vgl. ‚Niklas Legler‘ S. 11). Insgesamt wurden 472 verschiedene Personen erfasst.
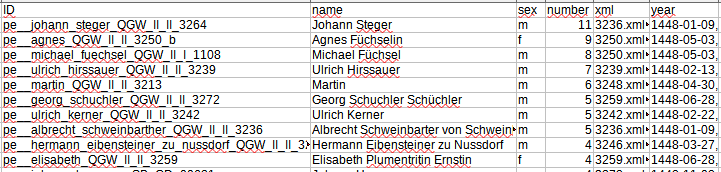
Abbildung 3: Screenshot der aus der Datenbank generierten Tabelle extractedpersons.csv. Von Links: ID = ID; Name = name; Anzahl der Nennungen = number; Geschlecht = sex; Quelle und Jahr der Nennungen = xml bzw. year
Ebenso verhält es sich mit der in Abbildung 4 sichtbaren Übersichtstabelle zu den Organisationen, in welcher statt dem Geschlecht die Art der Organisation verzeichnet ist. Die Aufteilung in ref und corresp zeigt an, ob eine Organisation in der Quelle als Körperschaft (z.B. „der convent gemein“) oder über eine Amtsperson auftritt. Insgesamt wurden 78 verschiedene Organisationen erfasst.
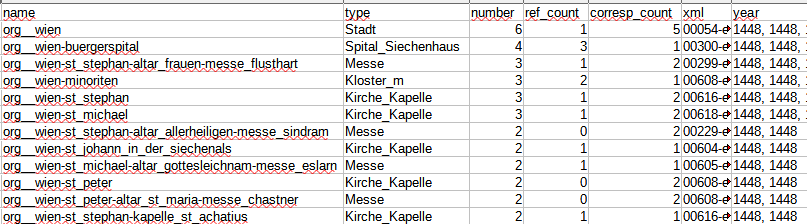
Abbildung 4: Screenshot der aus der Datenbank generierten Tabelle RefCorrespOrganisations.csv. Von Links: ID = ID; Art = type; Anzahl der Nennungen = number; Anzahl der ref-Nennungen = ref_count; Anzahl der corresp-Nennungen = corresp_count; Quelle und Jahr der Nennungen = xml bzw. year.
Abbildung 5 enthält die Übersichtstabelle der Orte, in welcher statt der Art der Organisation der Ortestyp verzeichnet ist. Die Aufteilung in ref und corresp zeigt an, ob der Ort direkt in das Rechtsgeschäft involviert ist oder nur als Referenzpunkt dient. Insgesamt wurden 284 verschiedene Orte erfasst.

Abbildung 5: Screenshot der aus der Datenbank generierten Tabelle extractedPlaces.csv. Von Links: ID = ID; regularisierter oder originaler Name des Orts = name_reg bzw. name_orig; Art = type; Anzahl der Nennungen = number; Anzahl der ref-Nennungen = ref_count; Anzahl der corresp-Nennungen = corresp_count; Quelle und Jahr der Nennungen = xml bzw. year.
Für die drei Entitäten lassen sich ebenfalls Detailtabellen jeder einzelnen Nennung erstellen. Im Falle der Detailtabelle der Personen nennen diese neben den Informationen zu Geschlecht, Titel, Beruf, staff– und off-Bezeichungen, auch die Funktion im Rechtsgeschäft, Quelle und Datum des Auftauchens sowie das frühest mögliche Todesdatum (Abbildung 6). Für alle aus dem Text extrahierten Informationen gibt es ebenfalls noch Spalten mit der entsprechend getaggten Textpassage (diese sind in der Tabelle aus Gründen der Übersichtlichkeit ausgespart). Insgesamt wurden 661 Personen getaggt.

Abbildung 6: Screenshot der aus der Datenbank generierten Tabelle extractedAllPersons.csv. Von Links: ID = ID; getaggte Textpassage (string) = text; Name = reg_name; Geschlecht = sex; Titel = titel_norm; relationale Titel = title_ref_norm; Beruf = prof_norm; Dienerschaft = staff_norm; Amt = off_norm; Funktion im event = fn_role; event = event_ref, Quelle und Datum des Auftauchens = xml bzw. date; frühest mögliches Todesdatum = earliest possible death.
Die Detailtabelle der Organisationen enthält neben den Hauptorganisationen auch deren Unterorganisationen sowie Informationen zur Art der Institution und der Ordenszugehörigkeit der Klöster, auch die Funktion im Rechtsgeschäft (Abbildung 7). Insgesamt wurden 102 Organisationen getaggt.

Abbildung 7: Screenshot der aus der Datenbank generierten Tabelle extractedAllOrganisations.csv. Von Links: ID der Überorganisation = main_ID; ID = ID; Name (regularisiert/original) = name_reg bzw. name_orig; Art = type; Observanz = observance; Art der Nennung (ref bzw. corresp = linking; Quelle und Jahr der Nennungen = xml bzw. year; Quellentext = text;.
Die Detailtabelle der Orte enthält neben den Informationen zur Art des Ortes und der Art der Verlinkung und auch die mögliche Funktion des Ortes im Rechtsgeschäft (Abbildung 8). Insgesamt wurden 575 Orte getaggt.
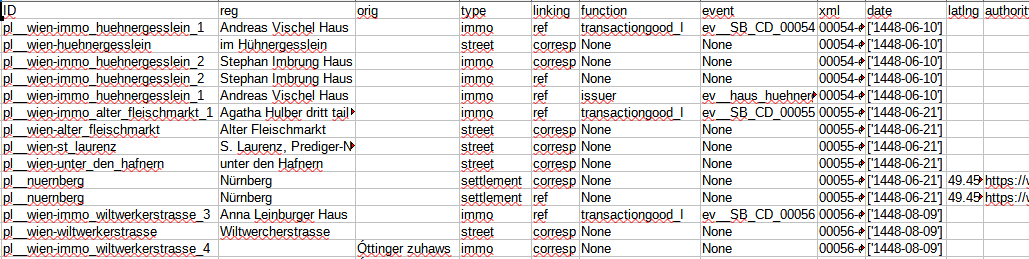
Abbildung 8: Screenshot der aus der Datenbank generierten Tabelle extractedAllPlaces.csv. Von Links: ID = name; Name (regularisiert/original = reg bzw. orig; Art = type; Art der Nennung (ref bzw. corresp = linking; Quelle und Jahr der Nennungen = xml bzw. year.
Für die relationalen Verbindungen können ebenfalls entsprechende Tabellen erstellt werden, welche die markierte Person, die Qualität der Beziehung (in diesem Fall normiert), die verknüpfte Person respektive Organisation (bei Amtsbeziehungen), sowie das Jahr und das Regest der Nennung beinhalten. Abbildung 9 zeigt die Tabelle der Verwandtschaftsbeziehungen mit den Elementen Name der Person, Art der Verwandtschaft, verwandte Person sowie Regest, Jahr und Datum des Auftauchens. Insgesamt wurden 173 Verwandtschaftsbeziehungen ausgezeichnet.

Abbildung 9: Screenshot der aus der Datenbank generierten Tabelle kinRelations.csv. Von Links: Person = ID; Geschlecht = sex; Quellentext der Verwandtschaftsbeziehung = off; normierte Art der Verwandtschaftsbeziehung = norm; ID der verwandten Person = related_ID; Geschlecht der verwandten Person = rel_sex; Quelle, Jahr und Datum des Auftauchens = xml bzw. year bzw. date.
In Abbildung 10 ist die Tabelle der Amtsbeziehungen dargestellt mit den Elementen Name der Person, Art der Amtsbeziehung, verbundene Institution oder Person sowie Quelle, Jahr und Datum des Auftauchens. Insgesamt wurden 145 Amtsbeziehungen ausgezeichnet.
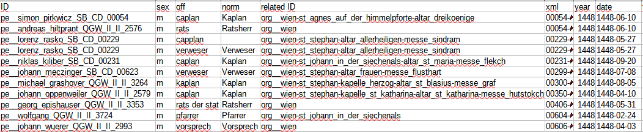
Abbildung 10: Screenshot der aus der Datenbank generierten Tabelle offRelations.csv. Von Links: ID = ID; Geschlecht = sex; Quellentext der Amtsbeziehung = off; normierte Art der Amtsbeziehung = norm; Institution oder Person = related_ID; Quelle, Jahr und Datum des Auftauchens = xml bzw. year bzw. date.
Abbildung 11 enthält die Tabelle der aus rechtlichen Vertretungen entstehenden Beziehungen mit den Elementen Name der Person, Art der rechtlichen Vertretung, rechtliche/r Vertreter/in sowie Quelle, Jahr und Datum des Auftauchens. Insgesamt wurden 60 Vertretungs-Beziehungen ausgezeichnet.

Abbildung 11: Screenshot der aus der Datenbank generierten Tabelle repRelations.csv. Von Links: Person = ID; Geschlecht = sex; Quellentext der Repräsentativbeziehung = rep; normierte Art der Repräsentativbeziehung = norm; ID der verbundenen Person = related_ID; Geschlecht der verbunden Person = rel_sex; Quelle, Jahr und Datum des Auftauchens = xml bzw. year bzw. date.
In Abbildung 12 ist die Tabelle der titularen Beziehungen dargestellt mit den Elementen Name der Person, Art der titularen Beziehung, verbundene Institution oder Ort sowie Quelle, Jahr und Datum des Auftauchens. Insgesamt wurden 84 titulare Beziehungen ausgezeichnet.

Abbildung 12: Screenshot der aus der Datenbank generierten Tabelle title_refRelations.csv. Von Links: Person = ID; Geschlecht = sex; Quellentext der Titelbeziehung = off; normierte Art der Titelbeziehung = norm; ID der/des verbundenen Organisation/Ortes = related_ID; Quelle, Jahr und Datum des Auftauchens = xml bzw. year bzw. date.
In Abbildung 13 ist die Tabelle der topographischen Beziehungen von Orten zueinander dargestellt mit den Elementen Name der Person, Art der Amtsbeziehung, verbundene Institution oder Person sowie Quelle und Jahr des Auftauchens. Insgesamt wurden 265 topographischen Beziehungen ausgezeichnet.

Abbildung 13: Screenshot der aus der Datenbank generierten Tabelle topoPlaceRelations.csv. Von Links: ID = ID; Name = name; Quellentext der topographischen Beziehung = rel_text; ID des verbundenen Ortes = rel_ID; Quelle und Datum des Auftauchens = xml bzw. date.
Abbildung 14 veranschaulicht die besitzrechtlichen Beziehungen (nucz und gewer) von Personen und Orten. Insgesamt wurden 237 besitzrechtlichen Beziehungen ausgezeichnet.

Abbildung 14: Screenshot der aus der Datenbank generierten Tabelle ownerPlaceRelations.csv. Von Links: ID = ID; Name = name; Quellentext der besitzrechtlichen Beziehung = rel_text; ID der verbundenen Person = rel_ID; Quelle und Datum des Auftauchens = xml bzw. date.
8. Ausblick
Über die hier vorgestellten deskriptiven Beschreibungen sind weitere Auswertungen möglich. Als erstes von zwei Anschauungs-Beispielen wurden die Tabellen zu den places (topographische Verlinkung und eigentumsrechtliche Verlinkung) als Grundlage genommen und sozusagen ‚Liegenschaftsketten‘ gebildet, mit Straßen/Plätzen verbunden und die erwähnten Besitzer/innen hinzugefügt (Liegenschaften sind blau, Straßen/Plätze orange).

Abbildung 15: Screenshot eines Ausschnitts des aus der Datenbank generierten Netzwerks placeRelations.png: Strassen/Plätze = gelb; Liegenschaften = blau; das linke pop-up zeigt die ID des Beitzers/der besitzerin und Quellen des vorkommens der Liegenschaft; das rechte pop-up zeigt den Textausschnitt der nachbarschaftlichen Verbindung.
In der Infobox links (der Darstellung) werden einige Informationen des jeweils aktuell angewählten Knotens gezeigt, wobei natürlich noch nicht alle Informationen, die über den Ort erfasst sind, aufgezählt werden.
Dem zweiten Anschauungs-Beispiel wurde die Aussteller/in-Empfänger/in-Verknüpfung zugrunde gelegt und zielgerichtet verbunden (Personen sind im Beispiel orange, Organisationen blau). Dies ist möglich auf Basis eines RDF-Schematas, das aktuell entwickelt wird und zukünftig neben den csv-Tabellen als output-Option bestehen wird.
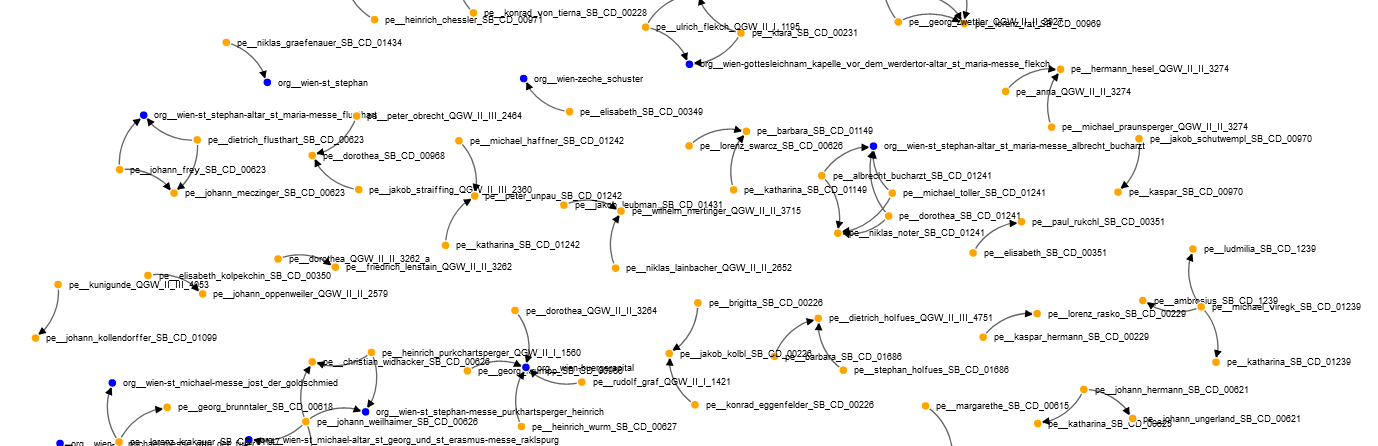
Abbildung 15: Screenshot eines Ausschnitts des aus der Datenbank generierten Netzwerks issuer-recipientRelations.png: persons = gelb; organisations = blau; die Pfeile veranschaulichen die Richtung des Rechtsgeschäfts.
Die Anlage dieser Datensätze ermöglicht neben eingehenden prosopographischen und netzwerkanalytischen Untersuchungen auch eine systematische topographische Weiterverarbeitung, indem zum Beispiel die gebildeten „Häuserketten“ mit archäologischen Befunden abgeglichen und deren Informationen in die Datenbank integriert werden. Ebenso ist es möglich die Beziehungsgeflechte und Interaktionen der Wiener/innen und ihrer Institutionen auf verschiedenen Ebenen zu veranschaulichen und mit prosopographischen und topographischen Informationen abzugleichen und anzureichern.
Die Konstruktion der Datenbank ist außerdem so variabel bzw. flexibel, dass sowohl weitere Quellenbestände in unterschiedlicher Intensität erfasst und inkludiert werden können, als auch diverse Möglichkeiten der Verknüpfung mit anderen Datenbanken oder Lexika bestehen (bereits teilweise integriert sind z.B. geonames.org und geschichtewiki.wien.gv.at. Inhaltlich und technisch ist das Gerüst für eine interaktive mittelalterliche Wien Karte mit prosopographischem Register und netzwerkanalytischen Visualisierungsoptionen fertiggestellt.26 Um dieses systematisch weiter zu befüllen und zu verlinken sowie einen öffentlichen Zugang zu ermöglichen, wollen die beiden Projekte zukünftig kollaborieren.
2Eine kurze Beschreibung der light-version der Artikel: Lutter, Christina/Frey, Daniel/Krammer, Herbert/Grünwald, Korbinian: Soziale Netzwerke im spätmittelalterlichen Wien. Geschlecht, Verwandtschaft und Objektkultur. MEMO_quer 2 (2021), doi: 10.25536/2021q002: https://memo.imareal.sbg.ac.at/wsarticle/memo/memo_quer/2021-quer-2-lutter-soziale-netzwerke/#nfootnote-bibliography-btm-59 (letzter Zugriff: 13.09.2021).
3Quellen zur Geschichte der Stadt Wien, Abt. 2: Regesten aus dem Archive der Stadt Wien (Hg.) Verein für Geschichte der Stadt Wien (Wien 1895-1937), II/1-3.
4https://grundbuecher.acdh.oeaw.ac.at/pages/index.html.
5Eine weitere Quellenart stellen die Wiener Stadtbücher dar.
6vgl. Bradley, John/Short, Harold: Texts into Databases: The Evolving Field of New-Style Prosopography. In: Literary and Linguistic Computing 2005 (20), S. 3–24., doi: https://academic.oup.com/dsh/article-abstract/20/Suppl/3/1027872?redirectedFrom=fulltext, S. 9ff.
7 https://factoid-dighum.kcl.ac.uk/.
8 Das Auszeichnen oder Markieren von Textpassagen (strings) wird in den DH als taggen bezeichnet.
9 Das Beispiel ist dem Regest Nr. 3269 entnommen (QGW II/II, Nr. 3269), online unter: https://www.monasterium.net/mom/AT-WstLA/HAUrk/3269/charter (letzter Zugriff 19.04.2021).
10 Die Trennung durch ‘_’ ermöglicht eine systematische Auswertung nach jeder, zwei oder allen drei Kategorien.
11 Im Falle des im Jahre 1448 „mit Handen“ der Äbtissin des St. Klara zu Wien, Susanne Schweinbarthin, getätigten Verkaufs eines Weingartens lautet die Formulierung: “widmen sie aus dem Nachlasse Schrot’s zwei Weingärten: von ersten mit handen der erwirdigen geistlichen frauen swester Susannen der Sweinbarterin, abbtessin dacz sand Claren zu Wienn”. Vgl. Regest Nr. 3269 (QGW II/I, Nr. 3269) online unter: https://www.monasterium.net/mom/AT-WStLA/HAUrk/3269/charter?q=3269 (letzter Zugriff 19.04.2021).
12Als owner werden in der bisherigen Erfassung Inhaber von „nucz und gewer“ einer Liegenschaft bezeichnet.
13Zur Art des Tagg siehe ‚Auszeichnungsschritt 5‘ S. 23: <roleName type=“off“ corresp=“org__oesterreich-herzogtum“ select=“pl__dornbach“>hofmaister</roleName> ze Dornpach</rs>, vgl. Regest Nr. 1584 (QGW II/I, Nr. 1584).
14Link zur roles_norm_matching-Tabelle: https://docs.google.com/spreadsheets/d/1_ygvqRnDTg6Rx2wp-RNPvZ3cKQFxfDPo3d7SBDiLO5c/edit#gid=0.
15Die Entität der events ist die einzige, welche noch keine nach Kategorien durchsuchbare ID-Konstruktion aufweist. Zur Identifizierung der Rechtsgeschäfte mittels der Funktionen von Oxygen ist deshalb ein baldiges Update nötig. Die ID-Konstruktion könnte dann in etwa so aussehen: ev__wien-immo_neuer_markt_1_satz_1_SB_CD_00226.
16 Vgl. Grundbucheintrag Nr. 00642 unter: https://grundbuecher.acdh.oeaw.ac.at/pages/show.html?document=e00642_1449-08-04.xml&directory=editions (letzter Zugriff 13.04.2021).
17 Link zur Vornamen_Normierung-Tabelle:
https://docs.google.com/spreadsheets/d/1a91QkqzNyPZ1OGXvx3IIyaT4VAQMoYG0ZX0dQLUUHaU/edit#gid=0.
18 Bei Frauen wird im Nachnamen die im Mittelalter übliche gegenderte Version verwendet.
19 Gibt es an einem Ort mehrere Pfarren, erfolgt die Unterscheidung (analog zu den Klöstern).
20 Bei Bürgerspitälern gibt fällt der „Eigenname“ (Bürger-) mit der Institutionellen Spezifikation zusammen.
21 Unterschied zu den übrigen IDs: durch die Nennung der Observanz wird „_kloster“ übersprungen bzw. direkt impliziert.
22 Die Namen der Stifter/innen werden wiederum nach demselben Schema wie bei den Personen normiert.
23 Die Kategorisierungen sind absichtlich sehr grob gehalten, wichtig war es zwischen Siedlungen, Straßen/Plätzen und Liegenschaften/Immobilien zu unterscheiden.
24Zur genaueren Beschreibung der Praxis der ‚Burgrechtsverkäufe‘ siehe u.a.: Czeike, F.,, Das Burgrecht in Wien im 15. Jahrhundert, in: Jahrbuch des Vereins für Geschichte der Stadt Wien (= JVGSW) 10 (1952/53) 115-137.
25Dies triff zu wenn ein Begriff für mehrere Personen verwendet wird oder ein Begriff zwei unterschiedliche Informationen enthält (z.B. muss „witib“ einmal als roleName type=“kin“ und einmal als roleName type=“dead“ ausgezeichnet werden).
26Das gemeinsam mit dem Projekt ‚Stadt und Gemeinschaft‘, dem Folgeprojekt „Soziale Netzwerke im mittelalterlichen Wien (PL Ch. Lutter) und den beiden Dissertationsprojekten von Daniel Frey und Herbert Krammer geführte Personenregister der Datenbank enthält bereits mehr als 7000 Einträge.
Kommentar schreiben