Trends in den Computational Literary Studies bei den DHd-Jahrestagungen
Die Computational Literary Studies (CLS) haben sich im vergangenen Jahrzehnt als ein dynamisches und zunehmend eigenständiges Forschungsfeld innerhalb der Digital Humanities etabliert. Die DHd-Jahrestagungen fungieren dabei nicht nur als Forum für aktuelle Diskussionen, sondern auch als Schaufenster für langfristige Entwicklungen, methodische Innovationen und disziplinäre Herausforderungen.
Etablierung der CLS in den Digital Humanities
Wie Hatzel et al. (2023, 1-2) in ihrem Übersichtsartikel „Machine Learning in Computational Literary Studies“ betonen, verstehen sich die CLS als ein Teilbereich der Digital Humanities, der sich durch die Anwendung computerbasierter Verfahren auf literaturwissenschaftliche Fragestellungen auszeichnet. Einen wichtigen Schub erhielten die CLS durch die Einrichtung des von der DFG geförderten Schwerpunktprogramms „Computational Literary Studies“ (SPP 2207) sowie durch die Gründung des Journal of Computational Literary Studies (JCLS) in der ersten Hälfte der 2020er Jahre.
In der deutschsprachigen DH-Community ist die wachsende Bedeutung der CLS auch an der Entwicklung der Tagungsformate der DHd ablesbar: Während CLS-relevante Beiträge in den frühen Jahrestagungen noch unter allgemeineren Titeln wie „Texte und Strukturen“ (2019) oder „Komplexe Textphänomene“ (2020) verhandelt wurden, tragen die Sessions seit 2023 explizit den Titel „Computational Literary Studies“. 2025 genügten bereits die Kürzel „CLS Analyse“, „CLS Methoden I“ und „CLS Methoden II“ – ein deutliches Signal für die gewachsene disziplinäre Eigenständigkeit und Sichtbarkeit des Feldes.
Angesichts dieser zunehmenden Etablierung stellte sich mir die Frage, welche methodischen Trends und inhaltlichen Entwicklungslinien sich in den Abstracts der DHd-Jahrestagungen von 2014 bis 2025 abzeichnen. Um relevante Beiträge zu identifizieren, habe ich basierend auf der Definition des Schwerpunktprogramms1 und einem Listenabgleich von Keywords, Topics und most distinctive Words (siehe Abb. 1) pro Beitrag CLS-relevante Abstracts automatisch aus den XML-Dateien extrahiert. Das so zusammengestellte Untersuchungskorpus wurde anschließend tabellarisch aufbereitet und mit den Metadaten aus den XMLs und manuellen Ergänzungen angereichert. Der Dataframe bildete sodann die Grundlage für interaktive Visualisierungen, die eine Exploration der CLS-Entwicklungen im Kontext der vergangenen DHd-Jahrestagungen ermöglichen.2
Welche CLS-Forschungstrends zeigen sich in den Abstracts der DHd-Jahrestagungen?
Ein zentrales Ergebnis der Analyse ist die methodische Breite der CLS, die von der Anwendung gängiger DH-Verfahren wie Netzwerkanalyse, Topic Modeling und Sentimentanalyse bis hin zu klassischem maschinellem Lernen und dem Einsatz generativer Sprachmodelle reicht. Die differenzierte Behandlung von Subkategorien des maschinellen Lernens stellte sich dabei als besondere Herausforderung heraus. Schließlich wollte ich die Entwicklungen und Höhepunkte traditioneller, feature-basierter Klassifikationsalgorithmen, multi-layered neuronaler Netze im Deep Learning sowie statistisch-kontextbasierter und generativer Sprachmodelle jeweils separat visualisieren. Ein Histogramm der verwendeten Methoden als Keyword-Cluster pro Abstract zeigt, welche Verfahren wann zum ersten Mal behandelt wurden, an Bedeutung gewinnen oder verlieren (siehe Abb. 2).
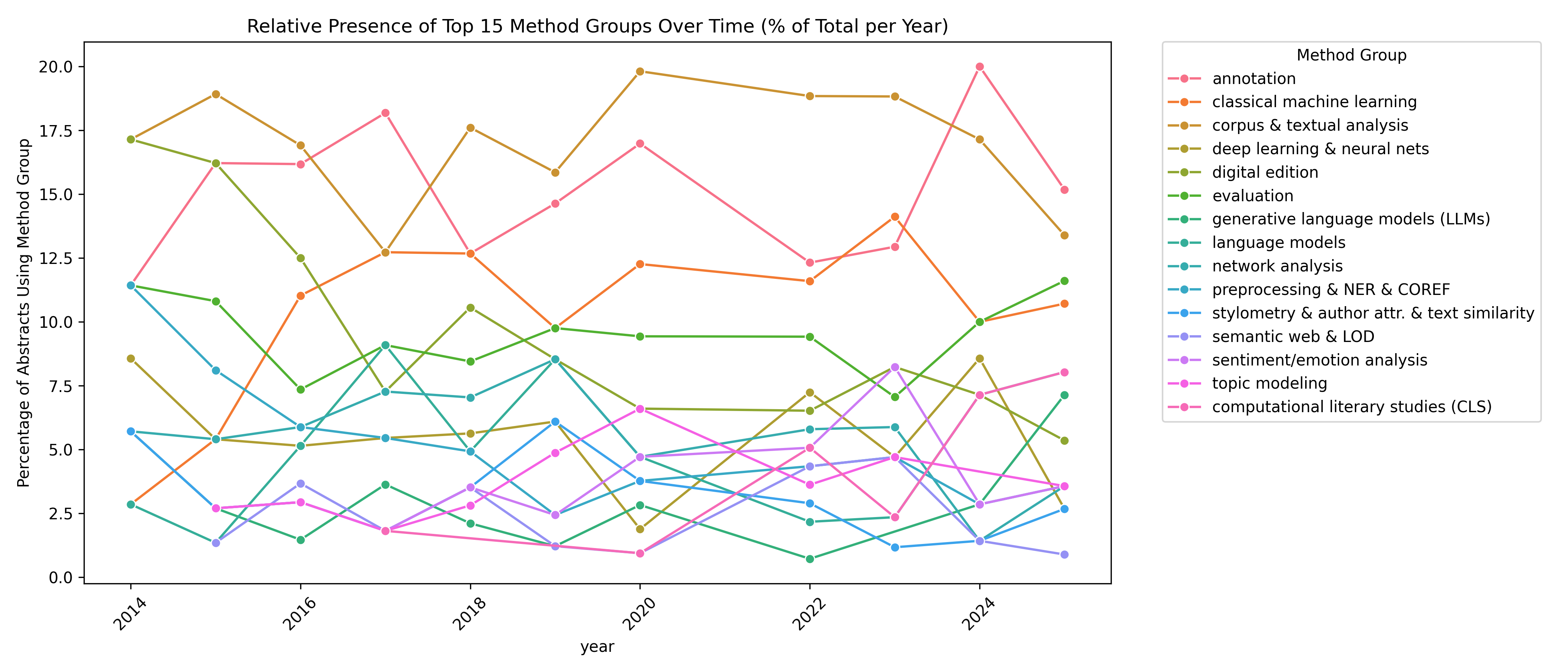
Das dargestellte Liniendiagramm (Abb. 2) zeigt die relative Nennung der 15 häufigsten Methodengruppen in den Abstracts (siehe Code). Die Y-Achse gibt den prozentualen Anteil an, den jede Methodengruppe im jeweiligen Jahr an der Gesamtzahl aller Abstracts hat und ermöglicht eine zeitlich normalisierte Betrachtung, bei der Schwankungen in der Gesamtanzahl der Abstracts pro Jahr berücksichtigt werden. Jeder Linienverlauf repräsentiert eine Methodengruppe und zeigt, wie oft sie im Verhältnis zur Gesamtzahl der Abstracts eines Jahres erwähnt wurde.
Die Abbildung verdeutlicht die konstruktive Weiterentwicklung der CLS: Zunächst müssen Textdaten aufbereitet und in geeigneter Qualität zur Verfügung gestellt werden, bevor sie analysiert und schließlich als Grundlage für das Finetuning von Sprachmodellen verwendet werden können. Nicht überraschend ist also der Peak an Abstracts zur Aufbereitung digitaler Editionen und Textkorpora in der Anfangszeit der DHd-Jahrestagungen sowie ihre andauernde Relevanz. In den Abstracts werden die digitale Bereitstellung von Texten, der Digitalisierungsprozess sowie die Entwicklung von Qualitätsstandards in OCR, XML/TEI und Normdatenanreicherung behandelt. War auch das Preprocessing in den Anfangsjahren noch ein zentraler Diskussionspunkt, wird es in den letzten Jahren bereits nicht mehr explizit in den Abstracts aufgeführt. Dieses Nichtaufführen im Fließtext weist auf die Etablierung von anerkannten Standards in der Datenvorbereitung hin und spricht für die Qualität von Preprocessinglibraries, Pipelines und ihren Ergebnissen.
Während auch Distinktivitäts- und Netzwerkanalysen zu den Verfahren gehören, die seit der ersten Jahrestagung vertreten sind, werden Topic Modeling und Sentimentanalyse erstmals 2015 erwähnt, sind seitdem aber nicht mehr wegzudenken, auch wenn sie seit ihren Höhepunkten (2020 Topic Modeling, 2023 Sentimentanalyse) tendenziell rückläufig sind. Die Blütezeit der CLS hat hingegen gerade erst begonnen: Nach einem ersten Peak 2022 (Zeitpunkt der Abstracteinreichung (Juli 2021) parallel zum Ende des ersten Jahres des DFG-SPP CLS) erzielt das Keyword-Cluster3 einen beeindruckenden Aufschwung mit kontinuierlich steigender Tendenz.
Ein klarer Aufwärtstrend zeigt sich auch bei „deep learning & neural nets“, die ab 2015 deutlich zulegen und sich als zunehmend wichtige Methode etablieren. Gemeinsam mit den differenzierten Keyword-Clustern „general machine learning“ und „generative language models (LLMS)“ bilden sie ein omnipräsentes Methodenrepertoire in den CLS.
Besonders auffällig ist, dass Annotationen über den gesamten Zeitraum hinweg ein zentrales Element bleiben, sei es als Grundlage manueller Analysen oder als Trainings- und Testdaten für maschinelles Lernen.
Und was ging bei der DHd2025?
Auf der Jahrestagung 2025 war die Präsenz der Computational Literary Studies unübersehbar. Ich besuchte die explizit als CLS ausgewiesenen Sessions „CLS Analyse“, „CLS Methoden I“ und „CLS Methoden II“, in denen zentrale Fragen der computergestützten Literaturwissenschaft diskutiert wurden. Darüber hinaus fanden sich CLS-relevante Vorträge auch in angrenzenden Formaten wie der Session „Large Language Models I“ und dem Doctoral Consortium. Besonders bemerkenswert ist auch, dass es dieses Jahr gleich zwei Panels zur digitalen Untersuchung von Literatur gab, was die zunehmende Sichtbarkeit und Relevanz des Feldes nochmals unterstreicht: interdisziplinär unter dem Titel „Gender (under) construction: Daten und Diversität im Kontext digitaler Literaturwissenschaft“ (Mende et al. 2025) und mit stärkerem Fokus auf das Computationale unter dem Titel „Literaturgeschichte ‚under construction‘ – was können die Computational Literary Studies beitragen? Ein Panel zur digitalen Untersuchung von Raum in der Literatur“.
Die Beiträge des Jahres 2025 spiegeln aktuelle Forschungstrends wider, die sich thematisch zwischen methodischer Validierung und dem produktiven Umgang mit Vagheit bewegen. Ein immer wiederkehrendes Thema ist dabei die Frage, wie literaturwissenschaftliche Konzepte so operationalisiert werden können, dass sie mit den Methoden der NLP analysierbar werden. Auch die Diskussion um Referenzkorpora und Qualitätsstandards für Annotationen war präsent: Während viele Projekte auf spezifisch zusammengestellte Korpora zurückgreifen, fehlt es nach wie vor an breit akzeptierten und annotierten Referenzkorpora. Hinsichtlich der Qualität von Annotationen schlug Janina Jacke (2025) einen „Platinstandard“ für kollaborativ erstellte, argumentativ begründete Annotationen mit Entscheidungsbäumen vor.
Ein innovativer methodischer Vorschlag kam von Julia Dudar und Christof Schöch (2025), die synthetische Texte als Kontrollgruppe verwendeten, um Analyseeffekte besser einordnen zu können. In diesem Zusammenhang wurden Stichprobenstrategien und Validierungsverfahren als offene Forschungsfragen thematisiert. Auch das Distinktivitätsmaß Zeta wurde wieder intensiv diskutiert und seine Leistungsfähigkeit erneut unter Beweis gestellt werden. Christof Schöch wies jedoch darauf hin, dass es nicht das eine perfekte Maß gebe, sondern es immer auf die zugrundeliegenden Fragestellungen und Korpora ankomme.
Ein weiteres Thema war die Segmentierung von Erzähltexten, etwa in Szenen oder andere narrative Einheiten – eine Herausforderung an der Schnittstelle von Linguistik und Narratologie, zu der Nora Ketschik (2025) treffend anmerkte, dass Prosatexte eben keine Dramen seien, die in der Regel schon von ihrer Textstruktur her eine sinnvolle Segmentierung mitbringen. Auch die Modellierung von Figuren und Perspektiven rückte stärker in den Fokus: Hier wurde betont, wie wichtig eine präzise Koreferenzauflösung ist, um zwischen handelnden und nur erwähnten Figuren zu unterscheiden, wenn Figurenbeziehungen in Netzwerken visualisiert werden sollen. Auch der Modellierung von Vagheit wurde in diesem Jahr wieder Aufmerksamkeit geschenkt: Julian Schröter (2025) stellte den c@1-Score vor, der es Modellen erlaubt, sich im Falle von Unsicherheiten zu enthalten – ein Verfahren, das er als besonders geeignet für vage literarische Kategorien vorstellte. Neu in der methodischen Diskussion war die Analyse gesprochener Literatur: Haimo Stiemer et al. (2025) untersuchten Pausen, Intonation und Prosodie in Hörbuchprosa mit Hilfe des Tools WhisperX, um Korrelationen zwischen Sprechpausen und narrativen Einschnitten zu identifizieren, die für einen neuen Ansatz der Textsegmentierung genutzt werden können.
Ein über einzelne Vorträge hinausgehendes immer wiederkehrendes Thema ist die Evaluierung (u.a. spezifisch behandelt in Pichler et al. (2025)), da sich mit zunehmender Anwendung generativer Modelle auch deren Fokus verschiebt: Neue Evaluationsmetriken und speziell kuratierte Testdatensätze gewinnen an Bedeutung, da herkömmliche, öffentlich verfügbare Daten aufgrund möglicher Pre-Training-Überschneidungen an Aussagekraft verlieren. Gerade im Hinblick auf generative KI in Annotationsprozessen stellt sich die Frage nach der Validität der Ergebnisse: Wie können wir sicher sein, dass, wenn die Annotation der 50 Beispiele aus unseren Testdaten erfolgreich war, die Annotationen auch darüber hinaus valide und nicht womöglich halluziniert sind?
Nicht zuletzt rückte auch die Rolle der CLS für die Literaturgeschichtsschreibung ins Zentrum der Diskussion (Panel von Herrmann et al. (2025)). Die Analyse größerer literarischer Korpora ermöglicht es, neue literaturgeschichtliche Narrative zu formulieren und kanonübergreifende Entwicklungen sichtbar zu machen. Dabei geht es nicht nur um die Datenmenge, sondern vor allem um die Verknüpfung von Textanalysen mit Kontextinformationen und Metadaten. Als neues Ideal der Literaturgeschichtsschreibung gilt die Einbeziehung der literarischen Kommunikation, so dass nicht nur eine Literaturgeschichte, sondern verschiedene Literaturgeschichten gleichzeitig geschrieben werden, ohne dabei das Einzelphänomen aus dem Blick zu verlieren.
Insgesamt zeigt die DHd2025 eindrucksvoll, wie weit die CLS innerhalb der Digital Humanities gekommen sind: Methodisch vielfältig, institutionell verankert und thematisch anschlussfähig erweisen sie sich als ein zentraler Baustein der digitalen Literaturwissenschaft, der nicht vor den schnelllebigen und sich ständig wandelnden Sprachmodellen zurückschreckt, sondern innovative Wege findet, neue Methoden produktiv in den Werkzeugkasten der CLS zu integrieren.
1 CLS „is dedicated to developi[n]g and establishing innovative computational methods in the field of literary studies. In this emerging rese[]a[r]ch field, literary scholars are working together with computer linguists and computer scientists to discover new perspectives on literary history, narratology and style analysis“ (SPP 2207 CLS, 2020).
2 Der verwendete Code befindet sich im GitHub Repositorium. Die XML-Versionen der DHd-Abstracts sind über die DHd GitHub Repositorien abrufbar. Mein besonderer Dank gilt Patrick Helling für die schnelle Bereitstellung der XML-Versionen der Jahrestagung 2025.
3 „computational literary studies (CLS)“: [„computational literary studies“, „CLS“, „computationelle literaturwissenschaft“, „komputationale literaturwissenschaft“, „literary computing“, „digitale literaturwissenschaft“, „digital literary studies“, „algorithmische literaturwissenschaft“]
Acknowledgements
Mein Dank gilt dem DHd-Verband, der mir durch ein Reisekostenstipendium die Teilnahme an der DHd2025 zum Thema „Under Construction“ in Bielefeld ermöglichte.
Referenzen
DHd-Verband (2025): DHd-Abstracts 2014 bis 2025 [GitHub Repositories], https://github.com/DHd-Verband.
Dudar, Julia and Christof Schöch (2025): “Exploring Measures of Distinctiveness: An Evaluation Using Synthetic Texts”. Book of Abstracts of DHd 2025, Zenodo. DOI: 10.5281/zenodo.14943110.
Guhr, Svenja (2025): CLS-Trends at DHd [GitHub Repository], https://github.com/SvenjaGuhr/CLS-Trends_at_DHd.
Hatzel, Hans Ole, Haimo Stiemer, Chris Biemann, and Evelyn Gius (2023): “Machine Learning in Computational Literary Studies”, it-Information Technology. DOI: 10.1515/itit-2023-0041.
Herrmann, Berenike, Daniel Kababgi, Marc Lemke, Nils Kellner, Ulrike Henny-Krahmer, Fotis Jannidis, Katrin Dennerlein, and Matthias Buschmeier (2025): „Literaturgeschichte ‚under Construction‘ – Was können die Computational Literary Studies beitragen? Ein Panel zur digitalen Untersuchung von Raum in der Literatur“. Book of Abstracts of DHd 2025, Zenodo. DOI: 10.5281/zenodo.14943254.
Jacke, Janina (2025): “Platinstandard-Annotation in der digitalen Literaturwissenschaft: Definition, Funktionen und diskursive Argumentvisualisierung als Best-Practice-Beispiel”. Book of Abstracts of DHd 2025, Zenodo. DOI: 10.5281/zenodo.14943180.
Ketschik, Nora (2025): “Netzwerkanalysen Narrativer Texte – Ein Vorgehensmodell”. Book of Abstracts of DHd 2025, Zenodo. DOI: 10.5281/zenodo.15124132.
Mende, Jana-Katharina, Claudia Resch, Mareike Schumacher, Laura Untner, Imelda Rohrbacher, Elena Suarez Cronauer, Andrea Gruber und Frederike Neuber (2025): “Gender (under) Construction: Daten und Diversität im Kontext digitaler Literaturwissenschaft”. Book of Abstracts of DHd 2025, Zenodo. DOI: 10.5281/zenodo.14943036.
Pichler, Axel, Dominik Gerstorfer, Jonas Kuhn und Janis Pagel (2025): “Empirische Evaluation des Verhaltens von LLMs auf Basis sprachphilosophischer Theorien: Methode und Pilotannotationen”. Book of Abstracts of DHd 2025, Zenodo. DOI: 10.5281/zenodo.14943146.
Schröter, Julian (2025): „Zur Modellierung von Unsicherheit: Machine Learning und begriffliche Vagheit Am Beispiel der Novellen im 19. Jahrhundert“. Book of Abstracts of DHd 2025, Zenodo. DOI: 10.5281/zenodo.14943086.
SPP 2207 CLS (2020): Computational Literary Studies [Website], https://dfg-spp-cls.github.io.
Stiemer, Haimo, Hans Ole Hatzel, Chris Biemann und Evelyn Gius (2025): „Pause im Text. Zur Exploration semantisch konditionierter Sprechpausen in Hörbüchern“. Book of Abstracts of DHd 2025, Zenodo. DOI: 10.5281/zenodo.14943032.
Websites via Bluesky 2025-05-14 – Ingram Braun
[…] Trends in den Computational Literary Studies bei den DHd-Jahrestagungen […]
Das war die DHd2025! | DHd-Blog
[…] Svenja Guhr, Trends in den Computational Literary Studies bei den DHd-Jahrestagungen, 13. Mai 2025, in: DHd Blog, https://dhd-blog.org/?p=22316 […]