Workshop “Korpusbildung” der DHd-AG Zeitungen & Zeitschriften – ein Rückblick
Von Matthias Arnold, Nanette Rißler-Pipka und Torsten Roeder
In unserer Workshopreihe zu Methoden der Forschung zu digitalisierten historischen Zeitungen und Zeitschriften haben wir im letzten November – nach mehreren Workshops zu OCR und zu Metadaten (Ankündigungen und Berichte dazu auf der AG-Seite) – die Veranstaltungsreihe mit einem Workshop zur Korpusbildung fortgesetzt.

Der Workshop begann mit einer Vorstellung des im Oktober 2021 gestarteten Deutschen Zeitungsportals der Deutschen Digitalen Bibliothek durch Lisa Landes (Videoaufzeichnung des Vortrags). Sie stellte das Frontend vor und demonstrierte an einer Reihe von Suchbeispielen die besonderen Funktionalitäten des Portals, deren vier Schwerpunkte die Volltextsuche, der integrierte Viewer, verschiedene browsende Zugänge sowie eine stabile Referenzierbarkeit darstellen.
Im Zeitungsportal werden historische Bestände und Sammlungen aus den letzten vier Jahrhunderten zusammengeführt und frei zur Verfügung gestellt. Dort sind 247 Zeitungen, 591.837 Zeitungsausgaben und zusammen 4.464.846 Zeitungsseiten (Stand November 2021) aus neun Bibliotheken durchsuchbar. Das Angebot soll kontinuierlich ausgebaut werden und langfristig alle digitalisierten historischen Zeitungen umfassen, die in deutschen Kultur- und Wissenseinrichtungen aufbewahrt werden.
Beispielseite aus dem Zeitungsportal: Badische Presse vom 7. Oktober 1931
Die Daten des Zeitungsportals – Bilder, Volltexte und Metadaten – können auch über eine ausführlich dokumentierte offene API abgerufen und extern ausgewertet und weiterverarbeitet werden. Dazu ist lediglich die Erstellung eines API-Keys nötig, für den im Bereich „Meine DDB“ ein kostenfreies Nutzerkonto eingerichtet werden kann. Weitere Informationen und Antworten auf andere Fragen finden sich auf der entsprechenden Webseite.
Im Fokus des Workshops stand das Thema Korpusbildung in der Praxis. Dafür konnte die AG Z&Z die beiden Kolleginnen Sarah Oberbichler und Eva Pfanzelter aus dem EU-geförderten Horizon-2020-Projekt NewsEye: A Digital Investigator for Historical Newspapers (2018–2022) gewinnen. Eva Pfanzelter startete mit theoretischen Einführungen am Beispiel historischer Fragestellungen aus dem Projekt mit dem Thema: Korpusbildung für geisteswissenschaftliche Fragestellungen. Sarah Oberbichler schloss daran ihren Vortrag zu Methoden für die Verbesserung der Repräsentativität von Korpora an. Anschließend ging es zusammen mit den Teilnehmenden an die praktische Arbeit der Korpuserstellung, bei der das NewsEye-Portal und eigens dafür eingerichtete Zugänge verwendet wurden.
Such- und Filterseite des NewsEye-Portals
Mit Hilfe von Jupyter Notebooks, die via myBinder eine interaktive Arbeitsumgebung zulassen, wurden am zweiten Tag verschiedene NLP-Methoden ausprobiert. Dabei wurden konkrete Fragestellungen bezüglich der Eindeutigkeit von Suchbegriffen aufgegriffen. Anhand von Forschungsfragen bezüglich Genre oder Diskurs (beispielsweise im Bereich Medizin oder Migration) wurden verschiedene Workflows praktisch ausprobiert.
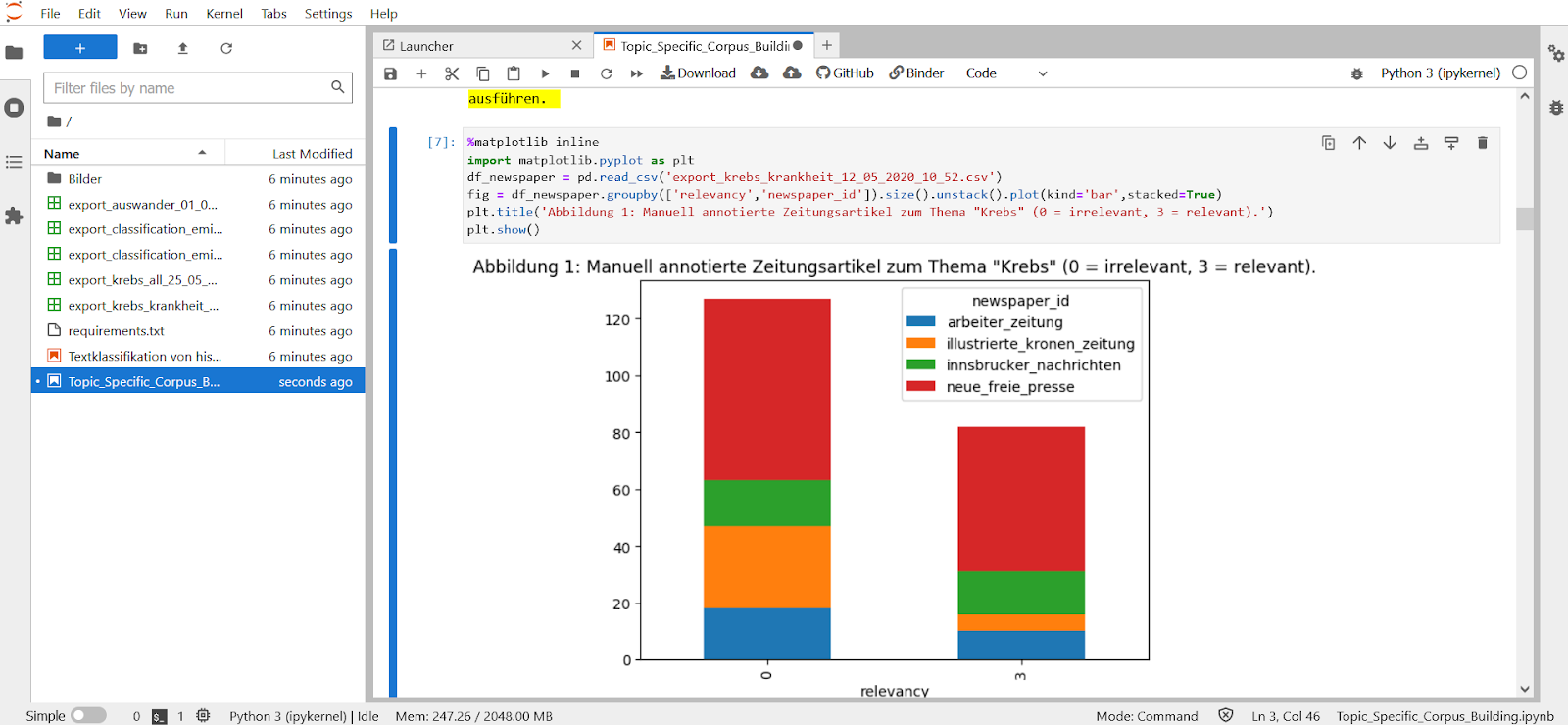
Interaktives Jupyter Notebook zur Korpusbildung in der MyBinder-Umgebung
Insgesamt wurde deutlich, dass bei der Korpusbildung nicht nur im Bereich Zeitungen und Zeitschriften die Kontextualisierung des vorhandenen Materials und auch dessen notwendige Beschränkungen immer mitgedacht werden müssen. Das betrifft zum einen die Plattform, über die ein Korpus erstellt wird, sowie die Menge der darin verfügbaren Materialien. Es betrifft zum anderen aber auch den Kontext des Materials selbst, wie es Amalia S. Levi in ihrem Eröffnungsvortrag Filling the Gaps: Digital Humanities as Restorative Justice zur Jahrestagung der DHd 2022 ansprach.
Ebenso haben auch Zeitungen eine Agenda, wird ein bestimmtes Zielpublikum adressiert und arbeitet ein ganzer Stab an Editoren mit, die jeweils noch eigene Ansichten einbringen. Alle Schlüsse, die man aus den Analysen eines bestimmten Korpus zieht, müssen vor diesem spezifischen Hintergrund auf ihren inneren bias hin geprüft, hinterfragt und transparent gemacht werden. Andernfalls besteht die Gefahr, dass die bereits den Materialien innenliegenden Asymmetrien in der eigenen Forschung wiederholt und verstetigt werden. Jedoch setzt das voraus, dass zu bestimmten Perioden überhaupt (digitales) Material aufbewahrt und verfügbar gemacht wird. Dies ist, wie Eva Pfanzelter zu Beginn ihres Vortrags betonte, insbesondere für die Zeitungsforschung und Zeitgeschichte zu den Jahrzehnten nach den 1950ern noch eine sehr große Herausforderung, da diese Zeiträume in den Digitalisierungsstrategien derzeit noch kaum Berücksichtigung finden. Um hier die “digital dark decades” zu verhindern, ist noch viel zu tun – vielleicht kann das auch Thema eines zukünftigen Workshops der DHd AG Zeitungen und Zeitschriften werden.
Die Vorträge des Workshops wurden mitgeschnitten:
Das Deutsche Zeitungsportal (Lisa Landes):
https://zo-pandora.zo.uni-heidelberg.de/BJJ/player/00:00:01#embed
Korpusbildung für geisteswissenschaftliche Fragestellungen (Eva Pfanzelter):
https://zo-pandora.zo.uni-heidelberg.de/BJM/player/00:00:01#embed
Methoden für die Verbesserung der Repräsentativität von Korpora (Sahra Oberbichler):
https://zo-pandora.zo.uni-heidelberg.de/BJK/player/00:00:01#embed
Ausgewählte Literatur:
Deutsche Digitale Bibliothek. ‘Errichtung eines nationalen Zeitungsportals auf der Basis der organisatorischen und technischen Infrastruktur der Deutschen Digitalen Bibliothek (DDB) – „DDB-Zeitungsportal“’. Deutsche Digitale Bibliothek. 2017. https://pro.deutsche-digitale-bibliothek.de/downloads-links/dfg-antrag-zeitungsportal
Deutsche Digitale Bibliothek. ‘Ausbau und Optimierung des DDB-Zeitungsportals – („DDB-Zeitungsportal V. 2.0“)’. Deutsche Digitale Bibliothek. 2021. https://pro.deutsche-digitale-bibliothek.de/downloads-links/dfg-antrag-zeitungportal-2-projektphase
Oberbichler, Sarah, and Eva Pfanzelter. ‘Topic-Specific Corpus Building: A Step towards a Representative Newspaper Corpus on the Topic of Return Migration Using Text Mining Methods’. Journal of Digital History, no. 1 (October 2021). https://journalofdigitalhistory.org/en/article/4yxHGiqXYRbX.
Kommentar schreiben