Bleibt alles anders: 10 Jahre correspSearch
Seit 2014 sammelt correspSearch die Metadaten von edierten Briefen und stellt sie zur projektübergreifenden Recherche bereit. Pünktlich zum runden Geburtstag gibt es jetzt neue Features: Visualisierungen, Volltextsuche und einen SPARQL-Endpoint. Über 270.000 edierte Briefe sind recherchierbar. Grund genug, nicht nur die neuen Funktionen vorzustellen, sondern auch zurück zu blicken und zu schauen, was noch kommt.
Von Stefan Dumont, Sascha Grabsch, Jonas Müller-Laackman, Ruth Sander und Steven Sobkowski
Blick zurück
Vor zehn Jahren, genauer gesagt am 1. September 2014, ging correspSearch mit einer E-Mail an die TEI-Liste und einem DHd-Blogpost offiziell online. Die Initiative zum Webservice war im Februar 2014 im Workshop „Briefeditionen um 1800: Schnittstellen finden und vernetzen“ entstanden, der von Anne Baillot und Markus Schnöpf an der BBAW organisiert worden war. Dort stellte Peter Stadler die Überlegungen zum geplanten TEI-Element correspDesc vor und äußerte in diesem Rahmen auch die Idee, über ein Austauschformat Korrespondenzmetadaten aus Briefeditionen bereitzustellen und editionsübergreifend zu aggregieren (Stadler 2014).
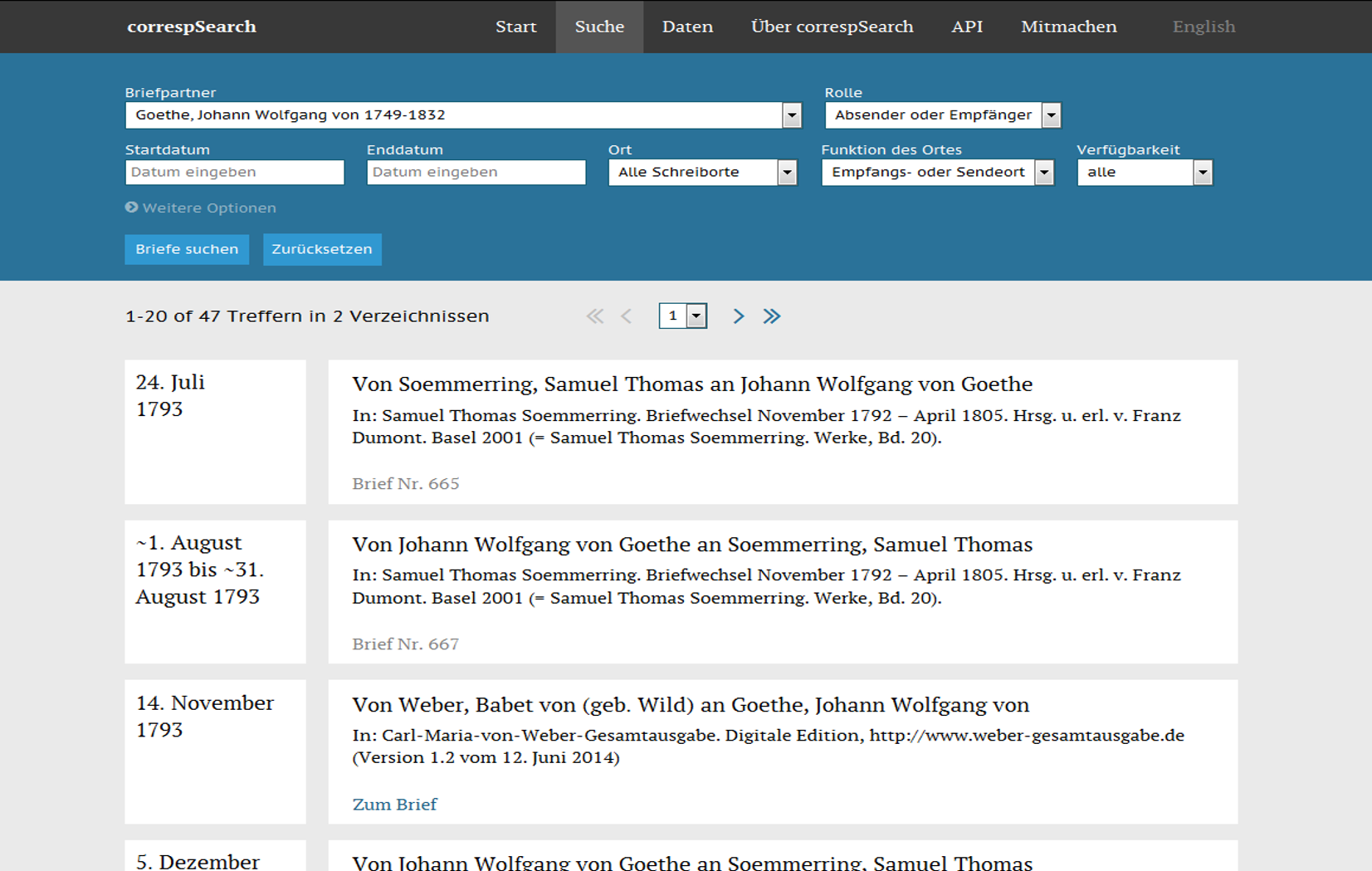
Im Nachgang zum Workshop wurde an der BBAW von Stefan Dumont der Prototyp eines Webservices entwickelt, der Dateien aggregieren und basal schon recherchierbar machen konnte: correspSearch (Dumont 2018; 2023). Gleichzeitig wurde von einer Taskforce der TEI Correspondence SIG die Modellierung von correspDesc abgeschlossen (Stadler, Illetschko und Seifert 2016). Mit dem Eingang von correspDesc in die TEI-Richtlinien (Version 2.8.0) im Frühjahr 2015 konnte auch das Correspondence Metadata Interchange Format (CMIF), das ebenfalls im Rahmen der TEI Correspondence SIG entwickelt wurde, in einer ersten Version finalisiert werden. Das CMIF setzt auf ein sehr reduziertes und restriktives Set an Elementen (und damit Informationen). Charakteristisch ist die konsequente Nutzung von URIs aus Normdateien wie der Gemeinsamen Normdatei (GND) für Personen und GeoNames für Orte. Dadurch können diese Entitäten projektübergreifend eindeutig identifiziert und gesucht werden.
Von Beginn an war correspSearch auf die Datenbereitstellung seitens der Editionsvorhaben, Forschungsprojekte und Institutionen angewiesen. Datenbeiträger der ersten Stunde waren z.B. die Weber-Gesamtausgabe und Briefe und Texte aus dem intellektuellen Berlin um 1800. In den folgenden Jahren wuchs der Datenbestand langsam, aber stetig an. Im Sommer 2016 konnten schon über 17.000 edierte Briefe nachgewiesen werden. Das – und die Auszeichnung von correspSearch mit dem Berliner DH-Preis 2015 – gab Rückenwind für die Beantragung eines DFG-Projekts. Der Antrag wurde dankenswerterweise positiv beschieden und das Projekt konnte 2017 starten.
Im Rahmen des DFG-Projekts wurde der Prototyp durch eine neue, modularisierte Softwarearchitektur ersetzt, die im Kern vor allem auf die Suchmaschinensoftware Elasticsearch setzt. Dadurch können auch sehr große Mengen an Meta- und Volltext-Daten (zu letzterem siehe weiter unten) performant durchsucht werden. Auch für Harvesting, Ingest und API wurden jeweils neue Applikationen entwickelt, die einen sicheren und stabilen Produktivbetrieb gewährleisten.
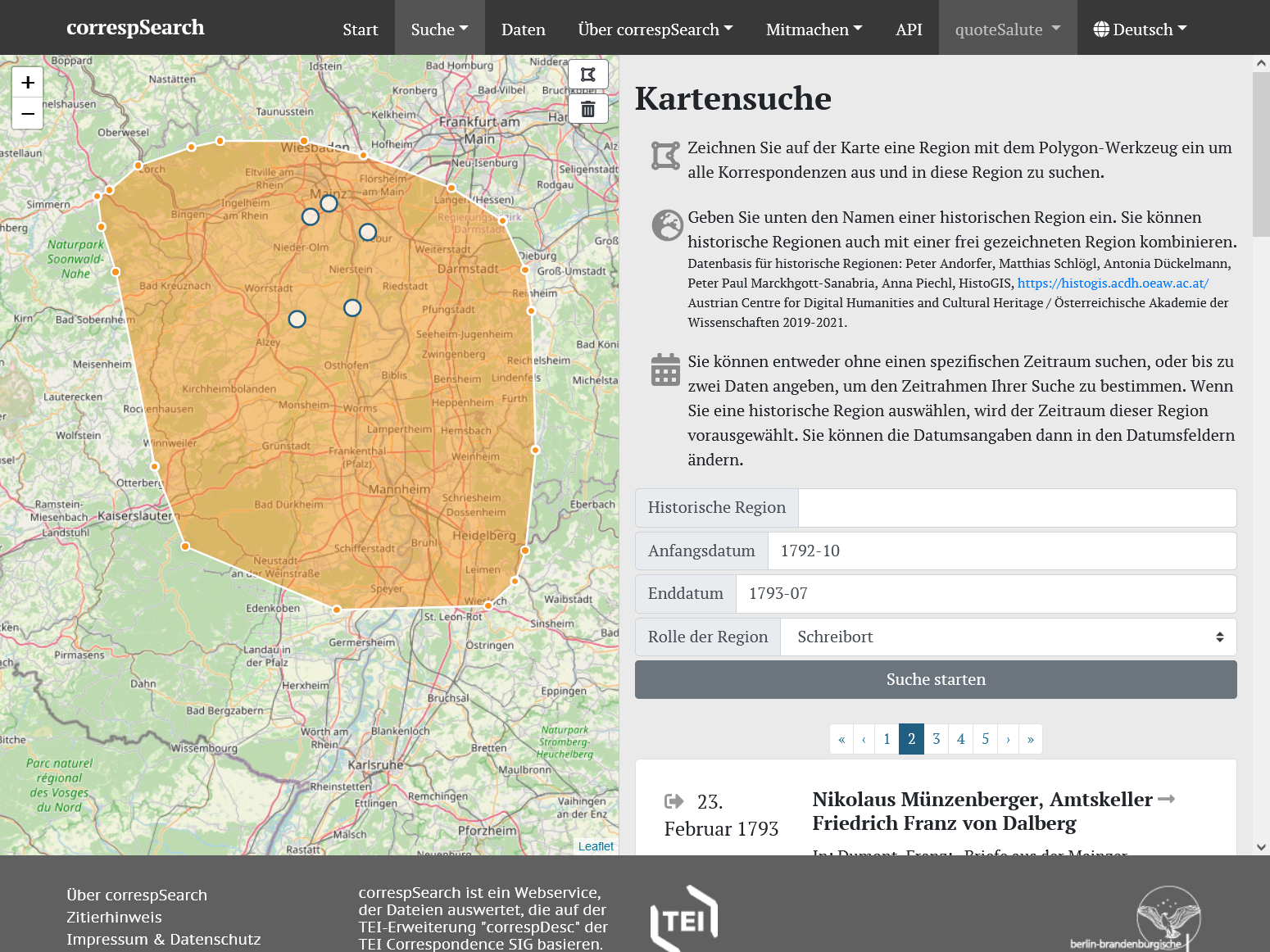
Die Software Elasticsearch ermöglichte auch eine facettierte Suche, so dass Suchergebnisse weiter exploriert und gefiltert werden können. Dabei wurden auch einige Filter entwickelt, die erst durch die Anreicherung der aggregierten CMIF-Daten mit weiteren Normdaten möglich werden. So können jetzt auch Briefe nach Geschlecht sowie Berufen ihrer Korrespondenten:innen recherchiert werden. Dazu nutzt correspSearch Daten aus der Gemeinsamen Normdatei und Wikidata nach. Mit Hilfe der von GeoNames bezogenen Geokoordinaten kann z.B. die kartenbasierte Suche benutzt werden. Hier kann nach Briefen anhand einer Region gesucht werden, die entweder frei eingezeichnet wird oder aus einem in HistoGIS vorgehaltenen, historischem Staatsgebiet (nach 1815) ausgewählt wird. Die neue Suchoberfläche wurde in Vue.js umgesetzt, die Website insgesamt ist nun responsiv und kann daher auf allen Endgeräten genutzt werden.
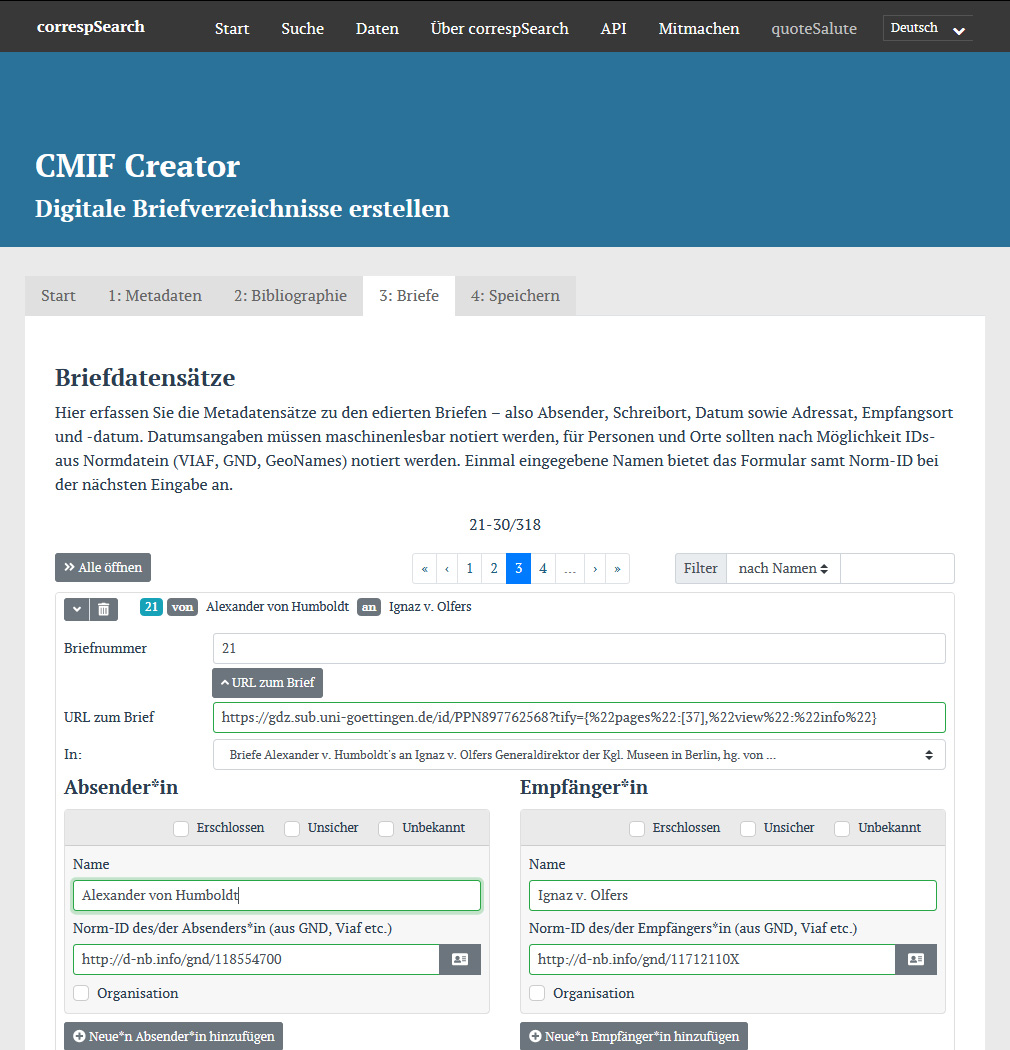
Darüber hinaus wurde mit dem CMIF Creator ein browserbasiertes Eingabeformular geschaffen, mit dessen Hilfe Wissenschafter:innen ohne technische Vorkenntnisse digitale Briefverzeichnisse ihrer Editionen erstellen können. Bei der Eingabe von Personen und Orten kann auch direkt bequem die GND bzw. GeoNames angefragt werden, um Normdaten-IDs für Personen und Orte zu ergänzen. Die Services CMIF Check und CMIF Preview unterstützen die Überprüfung von CMIF-Dateien. Außerdem wurden eigens Erklärvideos zu correspSearch und zum CMIF Creator produziert, die die bereits vorhandene Dokumentation ergänzen. Auch die Community stellte dankenswerterweise Tools für die CMIF-Erstellung bereit: So entwickelte Klaus Rettinghaus das Python-Tool CSV2CMI, das CSV-Tabellen in CMIF-Dateien umwandeln kann. Das Tool wird von der Sächsischen Akademie der Wissenschaften auch als Webservice angeboten – ergänzt um den Dienst ba[sic]?. Julian Jarosch (Akademie der Wissenschaften und der Literatur Mainz) entwickelte vor kurzem die eXistdb-Funktionsbibliothek CMIFerator, mit deren Hilfe eine CMIF API in eXistdb umgesetzt werden kann.
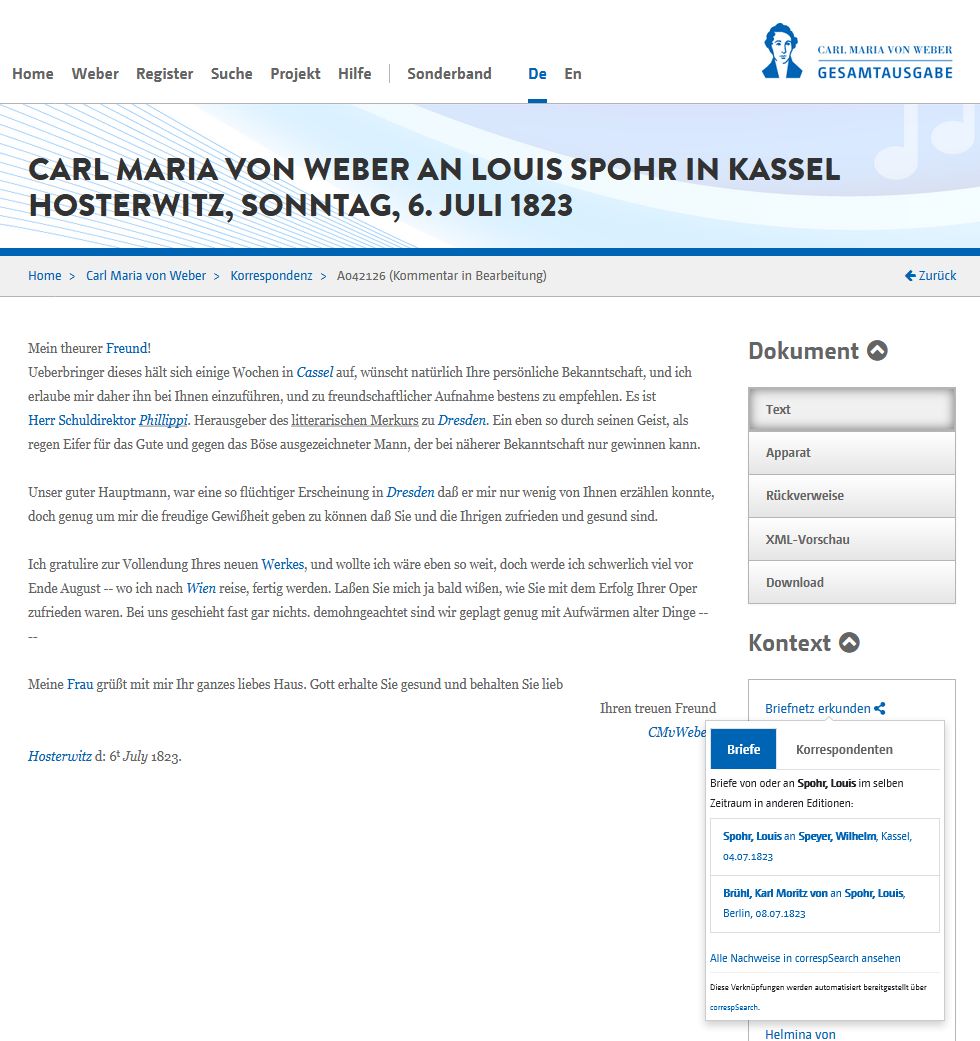
Im DFG-Projekt wurde außerdem das Javascript-Widget csLink entwickelt, das zu einem edierten Brief in der eigenen digitalen Edition auf zeitlich benachbarte Briefe der Korrespondenzpartner:innen aus anderen Editionen hinweist (dafür fragt es die API von correspSearch ab). Dieser ‚erweiterte Korrespondenzkontext‘ kann sehr interessant sein, denn eine Person kann über ein Ereignis etc. an verschiedene Korrespondenzpartner schreiben – und das unter Umständen auch mit unterschiedlichem Inhalt (Dumont 2023, 745). Das Widget csLink ist unter einer freien Lizenz publiziert und kann von jeder digitalen Edition nachgenutzt werden.
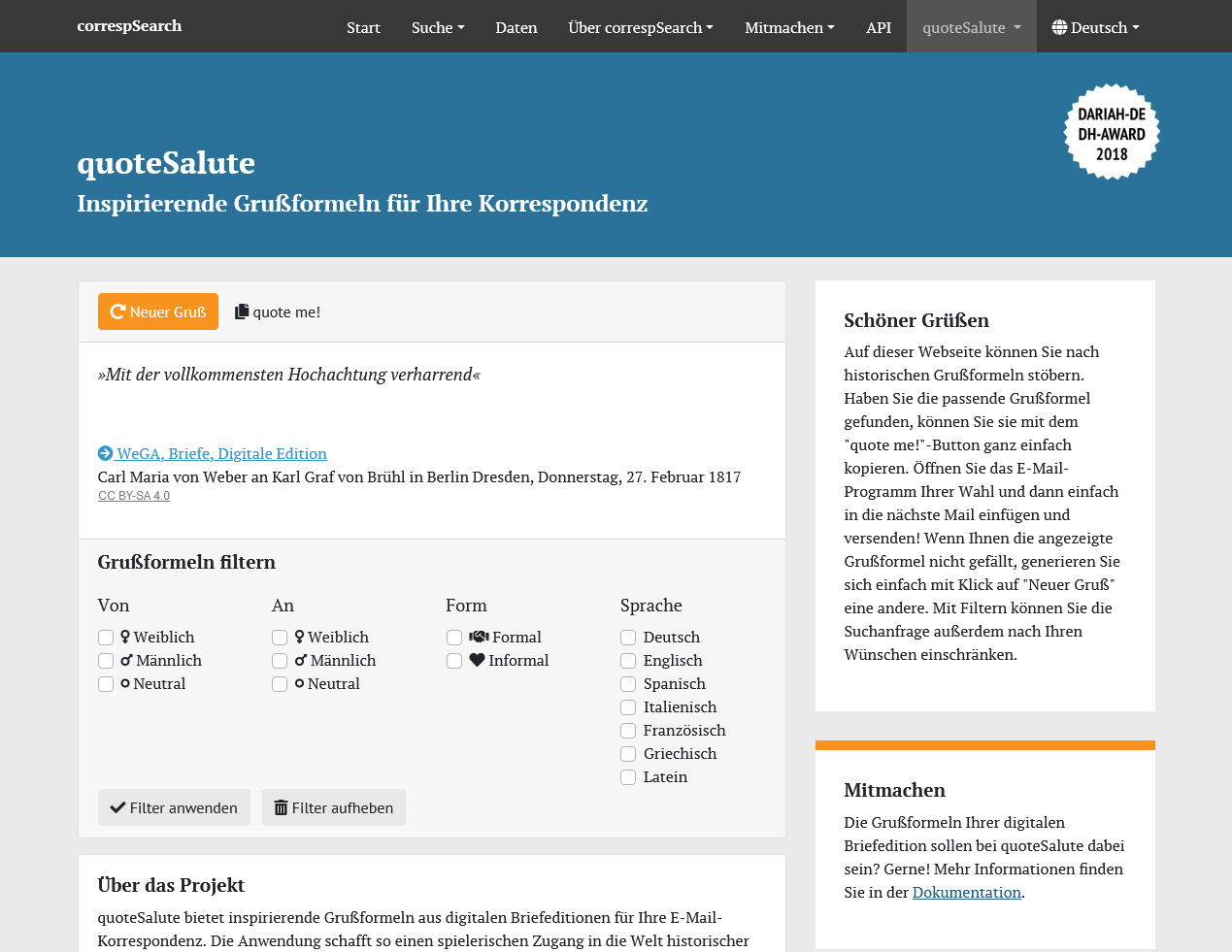
2018 kam ein kleines Nebenprojekt hinzu, das von Student:innen initiiert und umgesetzt wurde: quoteSalute (Lou Klappenbach, Marvin Kullick und Louisa Philipp, betreut von Stefan Dumont, Frederike Neuber und Oliver Pohl). Der Dienst quoteSalute bietet kuratierte Grußformeln aus edierten Briefen an, die in der eigenen (E-Mail-)Korrespondenz verwendet werden können (siehe hierzu auch den Artikel im DHd-Blog). QuoteSalute wurde mit dem DARIAH-DE DH-Award 2018 ausgezeichnet. Im selben Jahr wurde zudem der community-getriebene Projektverbund aus correspDesc, CMIF & correspSearch mit dem Rahtz Price for TEI Ingenuity der Text Encoding Initiative ausgezeichnet.
Im Laufe der vergangenen Jahre wuchs die Anzahl der in correspSearch nachgewiesenen Briefe durch zahlreiche Datenbereitstellungen – der größte Teil kam dabei aus der Fachcommunity, d.h. von den Editionsvorhaben und Institutionen selbst. Alle Datenbeiträger aufzuzählen würde den Rahmen dieses Blogbeitrags leider sprengen, aber einige sollen (neben den schon oben genannten) beispielhaft erwähnt werden: Alfred Escher-Briefedition, Alexander Rollett. Seine Welt in Briefen 1844-1903 (ZIM Graz), Briefe der Bach-Familie (Sächsische Akademie der Wissenschaften und Bach-Archiv Leipzig), Arthur Schnitzler – Briefwechsel mit Autorinnen und Autoren (M. A. Müller, G. Susen, L. Untner, ÖAW; nicht nur selbst edierte Briefe, sondern auch Metadaten zu Schnitzler-Briefen in anderen Editionen), Digitale Edition der Korrespondenz August Wilhelm Schlegels (J. Strobel & C. Bamberg), Briefe Friedrich Wilhelm Joseph Schelling 1786-1802 (BAdW), Melanchthon-Briefwechsel (Heidelberger Akademie der Wissenschaften), hallerNet, verschiedene Editionen, die im Rahmen des von Annika Rockenberger geleiteten Projekts Norwegian Correspondences (NorKorr) erfasst bzw. bereitgestellt wurden (z.B. zu Camilla Collet oder Edvard Munch), die Korrespondenz von Otto Nicolai (K. Rettinghaus), Hallesche Pastoren in Pennsylvenia (Franckesche Stiftungen), Briefe an Johann Wolfgang Goethe (Klassik Stiftung Weimar), Briefe von und an Theodor Fontane (Fontane-Archiv Potsdam), die Korrespondenz von Paul d’Estournelles de Constant (Anne Baillot & Team), The Mary Hamilton Papers (D. Denison et al.), das Thomas Gray Archive (R. Eck & A. Huber), CatCor – The Correspondence of Catherine the Great … die Liste ließe sich fortsetzen. Eine vollständige Übersicht aller CMIF-Dateien bzw. Publikationen kann hier eingesehen werden.
CorrespSearch ist für die aggregierten Daten übrigens keine Einbahnstraße: Der Webservice kann auch – übrigens bereits seit dem Launch 2014 – über APIs abgefragt und die Daten unter einer freien Lizenz maschinenlesbar abgerufen werden. Als Formate stehen TEI-XML, TEI-JSON sowie CSV zur Verfügung – in der API-Dokumentation können die Details eingesehen werden. Im Herbst 2023 wurde die technisch rundum erneuerte API 2.0 gelauncht, die auch bei großen Abfragen eine gute Performance gewährleistet. Darüber hinaus bietet eine BEACON-Schnittstelle die Möglichkeit, die in correspSearch nachgewiesenen Korrespondenzen automatisiert (etwa aus Personenregistereinträgen) zu verknüpfen. Und dank Klaus Rettinghaus steht auch in der (deutsch- und englischsprachigen) Wikipedia eine Vorlage bereit, um anhand der GND-ID von Wikipediaartikeln zu Personen aus zu deren Korrespondenzen in correspSearch zu verlinken.
Stand der Dinge: Version 3.0 mit Visualisierungen und Volltextsuche
Vor kurzem konnte das DFG-Projekt erfolgreich abgeschlossen werden und die Version 3.0 des Webservices correspSearch freigeschaltet werden. Damit einhergehend stehen nun auch neue Funktionen bereit. Neben Verbesserungen wie durchsuchbare Facetten, wurden auch zwei grundlegend neue Funktionen eingeführt.
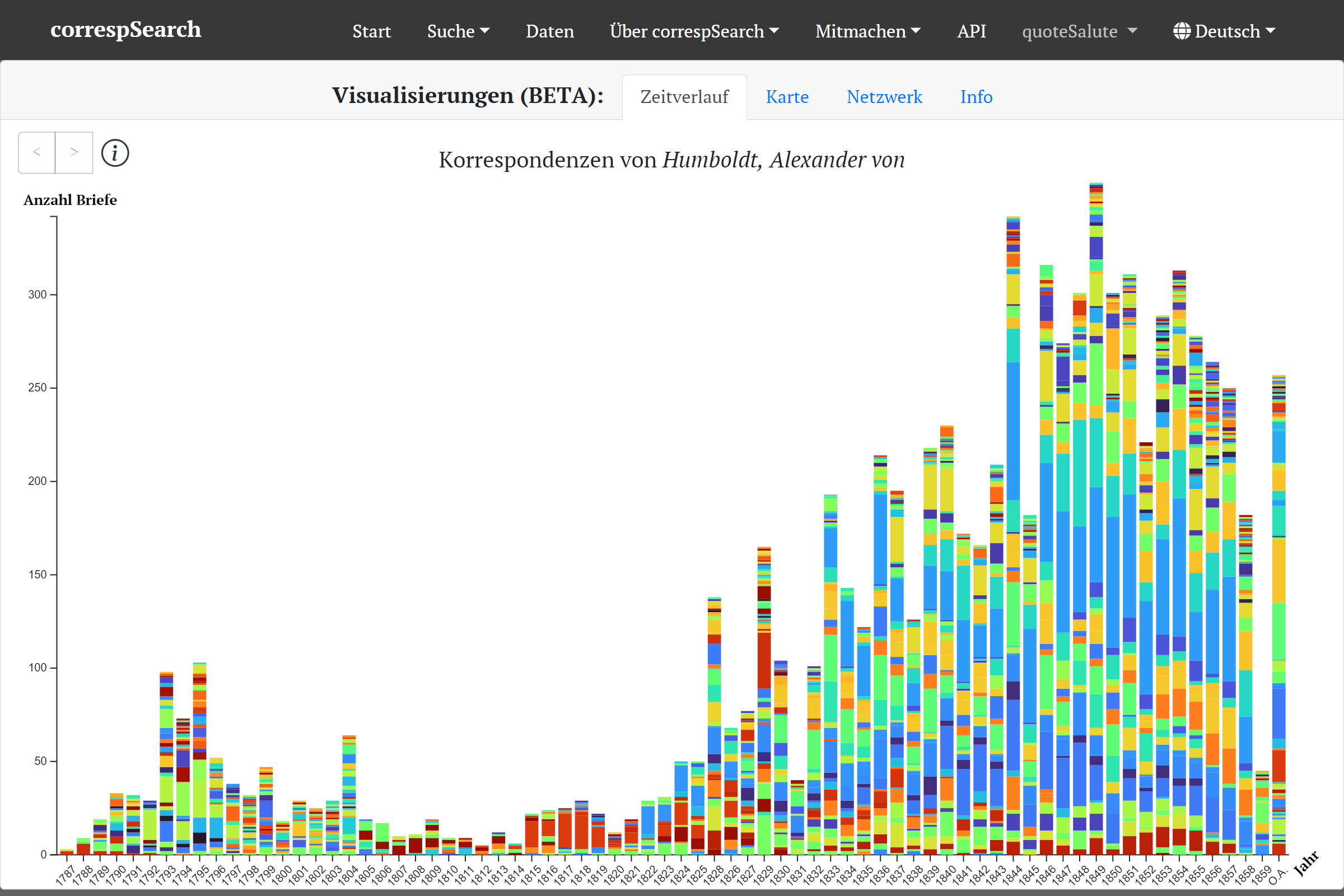
Zum einen können Suchergebnisse nun auch in Visualisierungen exploriert werden. Zur Auswahl stehen drei verschiedene Visualisierungstypen: Zeitverlauf (als gestapeltes Balkendiagramm) der Korrespondenzen, Kartenansicht der Schreib- und Empfangsorte (ebenfalls im Zeitverlauf) und Netzwerkdarstellung der Korrespondenzpartner:innen. Alle drei Visualisierungen können aus dem Suchergebnis heraus (also nach dem Ausführen einer initialen Suche) aufgerufen werden. Je nach Suche eignen sich die verschiedenen Visualisierung unterschiedlich gut für eine weitere Exploration. Während der Zeitverlauf gut für die Darstellung einer Gesamtkorrespondenz ist (etwa die von Constance de Salm-Salm), eignet sich die Kartenansicht besonders gut für Reisekorrespondenzen (etwa die von A. v. Humboldt 1829 in Russland).
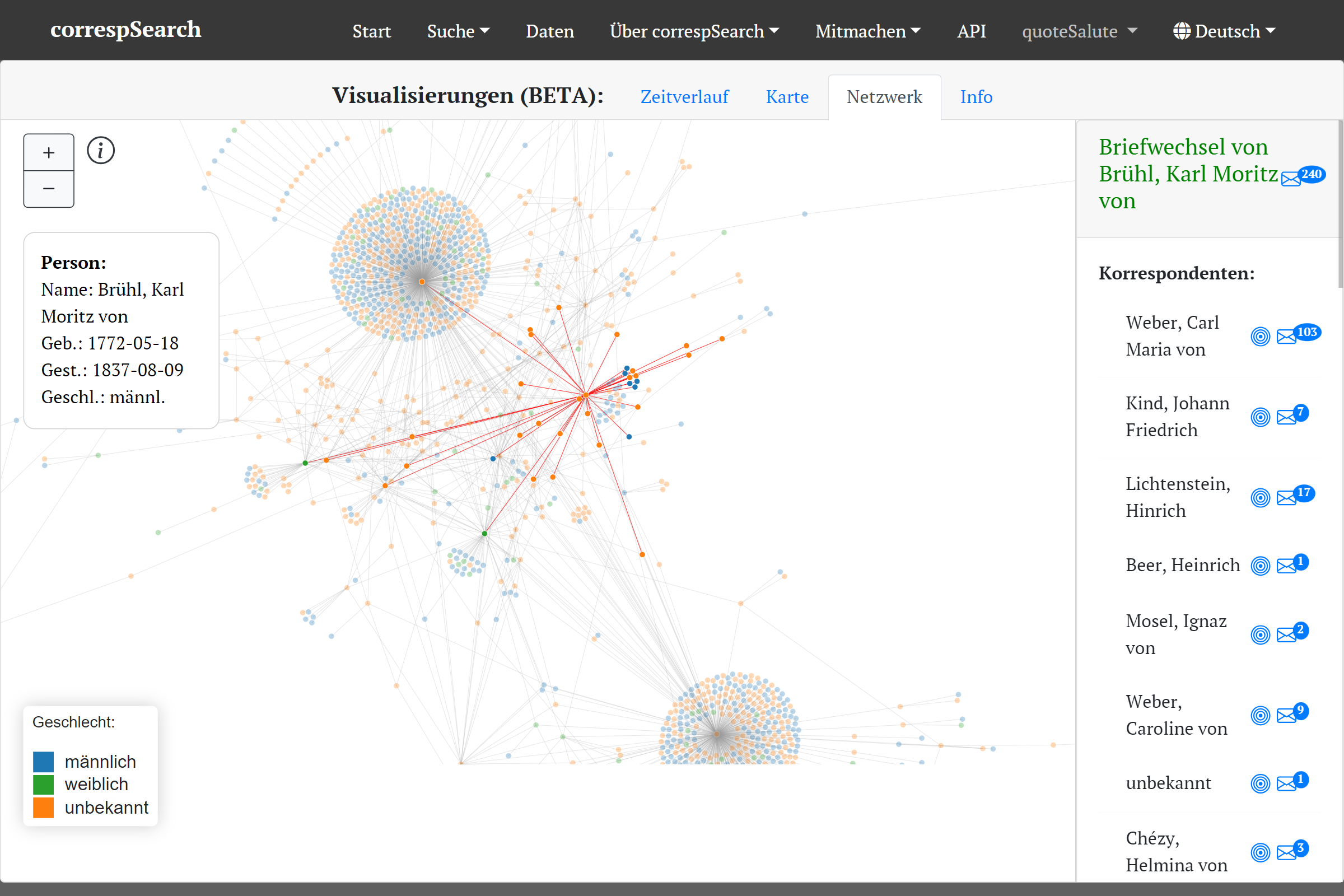
Die Netzwerkansicht dagegen ist interessant für nicht personenzentrierte Abfragen oder Editionen, die auch Briefe Dritter bzw. aus dem Umfeld enthalten (z.B. der Weber-Gesamtausgabe). Außerdem lassen sich mit ihr auch gut Briefnetze und Briefnetzwerke von ganzen Zeitschnitten erkunden (etwa 1789-1798). Allen Visualisierungen kann man durch Zoom-Funktion und Pop-Ups die zugrundeliegenden Metadaten entnehmen. Auch ist ein Wechsel zurück ins Suchergebnis für detailliertere Recherchen an vielen Stellen möglich. Das reibungslose “Switchen” vom Suchergebnis in die Visualisierung und zurück war ein zentraler Punkt im Konzept der Visualisierungen, die mit Hilfe von D3.js umgesetzt wurden.
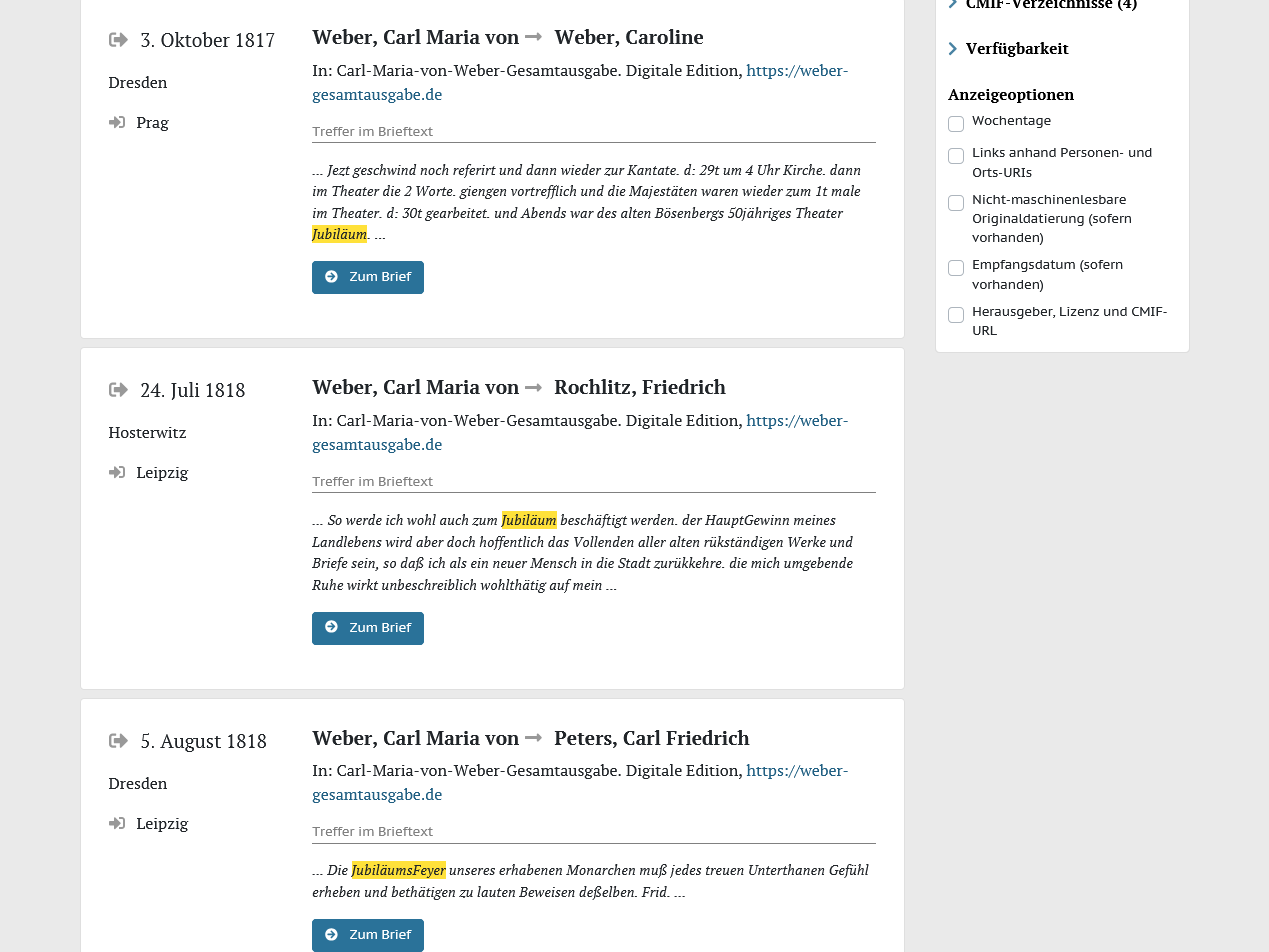
Zum anderen kann correspSearch nun neben den Metadaten auch die Volltexte der edierten Briefe harvesten, aggregieren und zur Recherche bereitstellen (z.B. für eine Suche nach “Jubiläum*”). Dabei wird im CMIF lediglich die URL zum TEI-XML-Volltext des jeweiligen Briefes angegeben und beim Ingest der Metadaten von dort bezogen. Digitale Editionen, die ihre Daten sowieso schon via API anbieten, können so leicht auch die Volltexte für correspSearch bereitstellen. Aber auch der Bezug der einzelnen Dateien aus Datendumps (etwa auf GitHub oder Zenodo) ist technisch grundsätzlich möglich. Beim Ingest werden TEI-Grundstrukturen ausgewertet und im Suchergebnis entsprechend angezeigt: So können Recherchierende Treffer im (originalen) Brieftext von denjenigen im Herausgeberkommentar oder Regest unterscheiden. Derzeit sind nur Texte aus den ersten vier digitalen Editionen recherchierbar, die dankenswerterweise bereits die CMIF-Schnittstelle entsprechend erweitert haben (u.a. Weber-Gesamtausgabe und Dehmel digital). Die Menge der im Volltext durchsuchbaren Briefe werden unter dem Suchschlitz der Volltextsuche angezeigt.
Neben der Volltextsuche werden die Suchfunktionen demnächst auch noch um eine weitere ergänzt: So kann man dann nicht nur nach Korrespondenzpartner:innen suchen, sondern auch nach erwähnten Personen. Die Funktion ist bereits fertig implementiert und wird in Kürze freigeschaltet. Sie basiert – wie die Volltextsuche – auf der Erweiterung des CMIF in Version 2 (Proposal, vgl. auch Dumont et al. 2019).
Mit der Version 3.0 von correspSearch wurde auch die API um eine weitere Schnittstelle erweitert: ab sofort können die Daten auch über einen SPARQL-Endpoint abgefragt werden. Dieser kann dankenswerterweise auf der Plattform lod.academy, die von der Akademie der Wissenschaften und der Literatur Mainz betrieben wird, angeboten werden. Das aktuelle RDF-Datenmodell ist dort ebenfalls dokumentiert. Zu beachten ist, dass der SPARQL-Endpoint derzeit noch als Betaversion betrieben wird und sich auch noch Änderungen am Datenmodell ergeben können.
Der Datenbestand konnte diesen Sommer auch wieder einen neuen Stand erreichen. Vor allem durch die Datenbeiträge aus der Editions- und Forschungscommunity, aber auch aus dem Kooperationsprojekt PDB18 (siehe dazu weiter unten) können aktuell über 270.000 Briefversionen recherchiert werden.
Bleibt alles anders
Das DFG-Projekt correspSearch – Briefeditionen vernetzen ist nun zu Ende gegangen, der Webservice wird aber durch die BBAW dauerhaft weiterbetrieben (BBAW 2023, 6). Außerdem läuft derzeit noch das DFG-Kooperationsprojekt Der deutsche Brief im 18. Jahrhundert (PDB18), das zusammen mit dem Interdisziplinären Zentrum für die Erforschung der Europäischen Aufklärung an der Universität Halle und der ULB Darmstadt durchgeführt wird. Ziel des Projekts ist es, eine Datenbasis und ein kooperatives Netzwerk zur Digitalisierung und Erforschung des deutschen Briefes in der Zeit der Aufklärung aufzubauen. Im Fokus des Projekts steht die Retrodigitalisierung bzw. Metadatenerfassung von gedruckten, abgeschlossenen Briefeditionen (Décultot et al. 2023).
Darüber hinaus wird der Webservice im PDB18-Teilprojekt an der BBAW um einige zusätzliche Funktionen erweitert (z.B. die Filter “Datenset” und “Verwendete Sprache”). Die wichtigste Entwicklung wird allerdings csRegistry werden. Mit csRegistry wird es möglich sein, für einen Brief (als “abstrakte” Entität) eine eindeutige URI zu vergeben und unterschiedliche Editionen dieses Briefes damit zu verknüpfen. Dadurch wird es in Zukunft möglich sein, verschiedene Editionen zu ein und demselben Brief in correspSearch anzeigen zu können bzw. diese “doppelten” Nennungen bei Bedarf aus den Daten herauszufiltern – etwa für die Netzwerkanalyse.
So wird die Zukunft noch ein paar Neuerungen für correspSearch bringen. Hoffentlich aber auch weiterhin viele neue digitale Briefverzeichnisse als CMIF, die den Datenbestand weiter anwachsen lassen. Denn auch wenn schon eine erkleckliche Menge an edierten Briefen in correspSearch nachgewiesen ist, die Masse der insgesamt edierten Briefe (allein im deutschsprachigen Raum) ist noch sehr viel größer. Daher ist auch ein Dienst wie correspSearch ohne die vielen großen und kleinen Datenlieferungen durch Editionsvorhaben, Wissenschaftler:innen und Institutionen nutzlos. Wir möchten uns daher an dieser Stelle für die zahlreichen Datenspenden der letzten 10 Jahre ganz herzlich bedanken. Und wer noch (oder wieder) Daten bereitstellen möchte, findet unter “Mitmachen” auf correspSearch.net alle weiteren Informationen.
Literatur
Berlin-Brandenburgische Akademie der Wissenschaften. 2023. “Das Leitbild Open Science der Berlin-Brandenburgischen Akademie der Wissenschaften.” urn:nbn:de:kobv:b4-opus4-37530.
Décultot, Elisabeth, Stefan Dumont, Katrin Fischer, Dario Kampkaspar, Jana Kittelmann, Ruth Sander und Thomas Stäcker. 2023. “PDB18: The German Letter in the 18th Century.” [Poster]. Encoding Cultures – Joint MEC and TEI Conference. Paderborn 2023. https://hcommons.org/deposits/item/hc:59731/
Dumont, Stefan. 2018. “correspSearch – Connecting Scholarly Editions of Letters.” Journal of the Text Encoding Initiative 10. https://doi.org/10.4000/jtei.1742.
Dumont, Stefan, Ingo Börner, Jonas Müller-Laackman, Dominik Leipold, Gerlinde Schneider. 2019. Correspondence Metadata Interchange Format (CMIF). In: Encoding Correspondence. A Manual for Encoding Letters and Postcards in TEI-XML and DTABf. Hg. v. Stefan Dumont, Susanne Haaf, and Sabine Seifert. URL: https://encoding-correspondence.bbaw.de/v1/CMIF.html URN: urn:nbn:de:kobv:b4-20200110163712891-8511250-2
Dumont, Stefan. 2023. “Briefeditionen vernetzen.” In Digitale Literaturwissenschaft: DFG-Symposion 2017, edited by Fotis Jannidis, 729–49. Germanistische Symposien. Stuttgart: J.B. Metzler. https://doi.org/10.1007/978-3-476-05886-7_30.
Stadler, Peter. 2014. “Interoperabilität von Digitalen Briefeditionen.” In Fontanes Briefe Ediert, edited by Hanna Delf von Wolzhagen, 278–87. Fontaneana 12. Würzburg: Königshausen & Neumann.
Stadler, Peter, Marcel Illetschko, and Sabine Seifert. 2016. “Towards a Model for Encoding Correspondence in the TEI: Developing and Implementing <correspDesc>.” Journal of the Text Encoding Initiative [Online] 9. https://dx.doi.org/10.4000/jtei.1742.
Update 10.09.2024: Hinweis auf Wikipedia-Vorlage für correspSearch ergänzt; Tippfehler korrigiert.
Update 13.09.2024: Hinweis auf CMIFerator ergänzt.
Werkstattreihe „Standardisierung von Forschungsdaten“ #03 correspSearch – Briefeditionen durchsuchen und vernetzen – Text+ Blog
[…] Für CMIF ist die Nutzung von URIs aus Normdateien wie der GND oder Geonames wichtig, um Personen und Orte projektübergreifend identifizierbar und somit auffindbar zu machen. Die neueste Version von CMIF stammt aus dem Jahr 2025. Eine Dokumentation der TEI Correspondence Special Interest Group befindet sich auf GitHub. […]