Einreichungen zur DHd 2018
Ulrike Henny-Krahmer (Würzburg), Patrick Sahle (Köln)
Die fünfte Tagung des Verbands DHd wird vom 26. Februar bis zum 2. März 2018 in Köln unter dem Motto “Kritik der digitalen Vernunft” stattfinden. Bereits eine gewisse Tradition hat die quantitative Auswertung von Einreichungen und ggf. auch Begutachtungen sowie Annahmen und Ablehnungen zu Konferenzen in den Digital Humanities. Beiträge zur internationalen DH-Konferenz der ADHO werden z.B. regelmäßig von Scott Weingart analysiert, aber auch die DHd-Einreichungen sind 2016 bereits von José Calvo Tello untersucht worden. Werden die eingereichten Beiträge kontinuierlich untersucht, können die Ergebnisse einen interessanten Überblick darüber geben, wie sich das Interesse an den Konferenzen entwickelt, welche Forschungsthemen im Zentrum der DH und welche Menschen, Orte und Institutionen hinter den Konferenzbeiträgen stehen. Handelt es sich vor allem um individuelle Forschung oder Arbeit im Team? Wie ist das Geschlechterverhältnis bei den Einreichungen? Woher kommen die Forschenden und welche Institutionen sind über Kooperationen miteinander verbunden?
Im Folgenden wird ein Export der Daten aus dem Konferenz-Managementsystem Conftool für die “Quantifizierung der DHd2018” verwendet. Mit den Basiszahlen werden einige grundlegende statistische Übersichten zu den Einreichungen gegeben. Im Fokus stehen außerdem die AutorInnen, AutorInnennetzwerke und Themen.
Basiszahlen
Zur Deadline der Konferenz DHd2018 am 25.09.2017, 1:00 Uhr sind insgesamt 187 Beiträge eingereicht worden, die sich wie folgt verteilen:
Tabelle 1: Beiträge nach Typen |
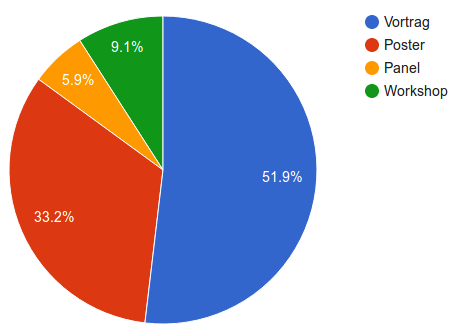
Abbildung 1: Anteile der Beitragstypen |
Dabei kommt nur ein gutes Viertel der Einreichungen von einzelnen Autoren. Knapp drei Viertel sind das Ergebnis von Teamarbeit:
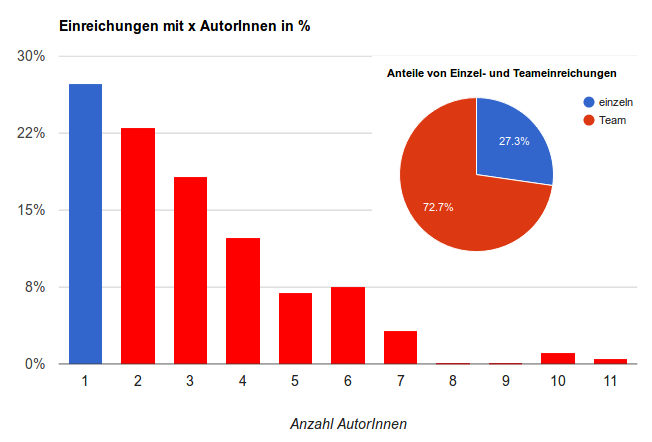
Abbildung 2: Anteile von Einzel- und Teameinreichungen
Wir folgen hier für die Vergleichbarkeit und für einen ersten Eindruck dem Ansatz von Scott Weingart, halten ein Liniendiagramm (wie er es einsetzt) aber für methodisch unzulässig, da es ja keine Zwischenstufen zwischen den Einreicherzahlen gibt. Wir verwenden daher ein Balkendiagramm. Ergänzend verdeutlicht das Kuchendiagramm die Anteile von Einzeleinreichungen (27,3%) im Vergleich zu Teameinreichungen (insgesamt 72,7%). Wie in Abb. 2 zu sehen, ist der allgemeine Trend, dass die Anzahl der Einreichungen mit der Teamgröße abnimmt.
Vergleicht man diese Zahlen mit den Verhältnissen bei den internationalen DH-Konferenzen, für die Weingart über die Jahre hinweg ähnliche Anteile feststellen konnte, so ist die Rate der Einzeleinreichenden bei der DHd2018 noch geringer als bei der globalen DH. Bei der DH2017 betrug sie z. B. 39,6 %. Zweiterteams hatten dort eine Quote von 24,5 % (DHd 23%), Dreierteams von 16,3 % (DHd 18,2%) und Vierer-Teams von 7,2 % (DHd 12,3%). Einreichungen von zwei AutorInnen gab es also bei der DH-Konferenz in Montréal noch geringfügig mehr als bei der DHd2018, Beiträge von größeren Teams sind aber bei der DHd-Konferenz häufiger vertreten.
Naheliegend ist die Frage, welchen Einfluss der Beitragstyp darauf hat, ob es sich um eine individuelle oder eine Teameinreichung handelt und wie groß die Teams sind. Die inhaltliche Frage lautet also eigentlich: wie verteilen sich die Einreicherkonstellationen auf die verschiedenen Arten von Beiträgen? Zu erwarten ist intuitiv eine höhere Koautorschaftsrate vor allem bei Panels und Workshops.
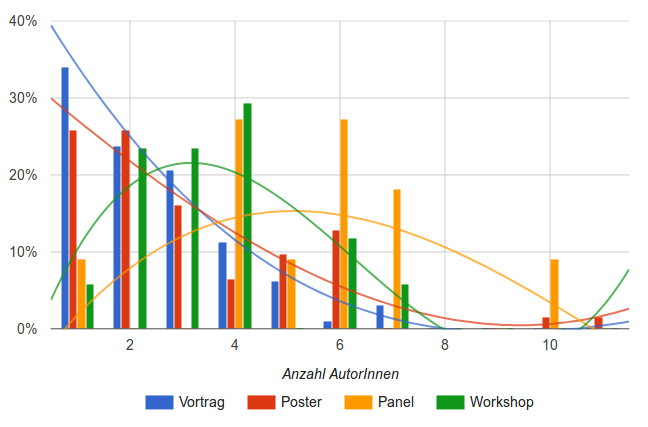
Abbildung 3: Einreichungen mit x AutorInnen in % (nach Beitragstyp)
Tatsächlich sind vor allem Vorträge individuell oder mit wenigen KoautorInnen eingereicht worden: 34% aller eingereichten Vorträge haben eine Autorin/einen Autor. Die höchste Zahl an Einreichenden wird allerdings nicht mit einem Panel oder Workshop, sondern mit einem Poster erreicht. Trotzdem sind je 25,8% der Poster-Einreichungen individuell oder mit zwei KoautorInnen erfolgt. Insgesamt ist der Verlauf für die Anzahl an AutorInnen bei Postern demjenigen bei Vorträgen relativ ähnlich. Anders sieht es bei Panels und Workshops aus, wo es keine relativ stetige Abnahme an Einreichungen mit höherer Koautorschaftszahl gibt, sondern einen höheren mittleren Bereich. Für Panels sind vier bis sieben Einreicher typisch (weil OrganisatorInnen und PanelistInnen häufiger zusammen einreichen?), bei Workshops liegt die Zahl der Einreichenden vor allem zwischen zwei und vier. Man beachte, wie hier stark geglättete Kurven genutzt werden, nicht um tatsächliche Zahlenwerte zu visualisieren, sondern einen zusammenfassenden, am grundsätzlichen Trend orientierten Eindruck zu geben.
Es scheint insgesamt sinnvoll, Typen von Gruppen festzulegen, um einen besseren Überblick über den Zusammenhang von Einreicherkonstellationen und Beitragstypen zu bekommen. Naheliegend ist hier eine Gruppierung in “Einzelbeitrag”, “Duo”, “Kleingruppe” (3-5) und “Großgruppe” (>5). Geht man davon aus, dass Panel und Workshops ihrer Natur nach ohnehin meistens von Teams organisiert werden (Einzeleinreichungen waren die Ausnahme), bleiben die Poster und Vorträge besonders interessant. Hier liegt die Quote der Einzeleinreichungen bei 26% (Poster) bzw. 34% (Vorträge). Auch der Durchschnitt der Autorenzahl mit 3,1 bei Postern und 2,5 bei Vorträgen zeigt, dass Poster in noch größerem Maße Teamarbeit als Vorträge sind. Für diese beiden Formate zeigen sich die folgenden Konstellationen:
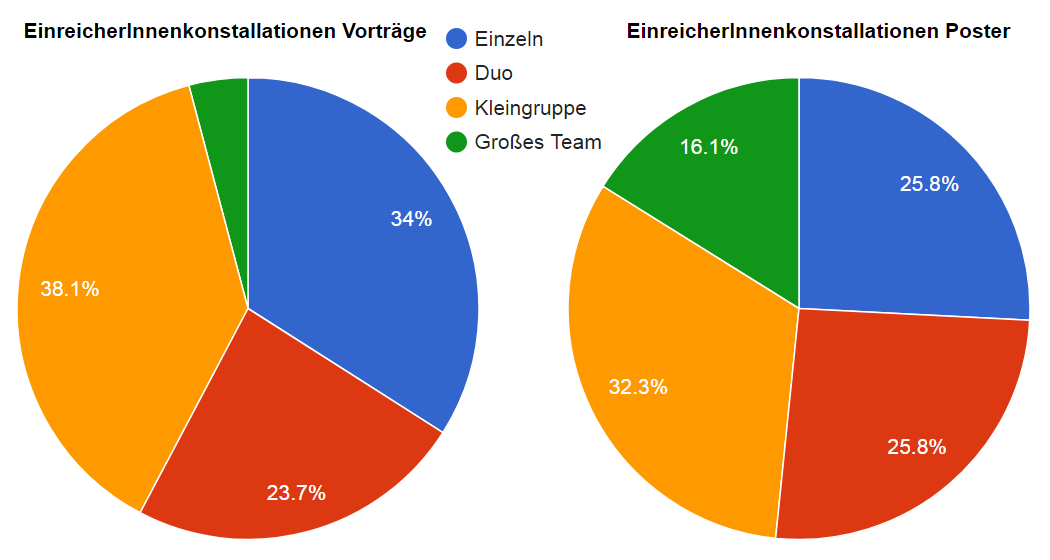
Abbildung 4: Einreicherkonstellationen für Paper und Poster
Eine mögliche Erklärung liegt wohl darin, dass Poster häufiger auf Projekte bezogen sind, die in den DH meistens in Teamarbeit durchgeführt werden. Dagegen sollten Vorträge eher einzelne Forschungsfragen behandeln. Dass selbst dabei die Quote der Einzelbeiträger nur ein Drittel beträgt, zeigt wie das Muster kollaborativer Forschung sich auch auf diesen Bereich erstreckt. Oder, dass auch die Vorträge in Wirklichkeit projektbezogen sind. Aber um das zu untersuchen, müsste man die Daten weiter anreichern und die Vortragsthemen klassifizieren.
AutorInnen
Die Beiträge haben insgesamt 553 AutorInnen, davon 449 verschiedene. 62 AutorInnen waren an zwei Beiträgen beteiligt, 19 an drei bis fünf Einreichungen. Diese Zahlen sind vor dem Hintergrund zu diskutieren, dass vom Programmkomitee folgende Vorgabe gemacht worden ist:
“In der Regel wird erwartet, dass von einem Verfasser/einer Verfasserin/einer Projektgruppe nur ein Poster oder Vortrag eingereicht wird. Eine Beteiligung von Beitragenden darüber hinaus an maximal einem Panel oder Workshop ist jedoch möglich.”
Diese Politik ist grundsätzlich nachvollziehbar, führt aber in einem stark kollaborativ orientierten Forschungsfeld zu einigen Folgeproblemen. Was macht man, wenn man an mehreren Projekten beteiligt ist? Dann können die Partner aus einem zweiten Projekt ja nicht dafür in Kettenhaftung genommen werden, dass die Partner in einem ersten Projekt schon etwas eingereicht haben, auf dem auch der eigene Name steht.
Die Deutung von Begriffen wie “oder” und “in der Regel” ist offenkundig von den Einreichenden vorgenommen und unterschiedlich getroffen worden. Außerdem könnte man argumentieren, dass es einen engen und einen weiten Begriff von “einreichen” geben kann: die Person, die hochlädt versus alle an einer Einreichung beteiligten. Wenn man von einem engen Begriff ausgeht, wäre es möglich, als Autor an beliebig vielen Einreichungen beteiligt zu sein, solange nur alle Einreicher (Hochlader) nur einmal als solche auftreten. Schließlich könnte man sich auch auf die Formulierung “von einer Projektgruppe” zurückziehen. Damit könnte man dann auch fünf Beiträge einreichen, wenn man an fünf Projekten beteiligt ist.
Will man die Community nicht in den Exegesesumpf schicken und die Folgsamen (“ich lese: nur ein Beitrag”) nicht gegenüber den Zügellosen (“Regeln? Doch nicht für mich!”) in Nachteil bringen, dann wären sicher auch einfachere und transparentere Regelungen und Formulierungen möglich:
- Eine strikte Maximalzahl von Gesamtbeteiligungen, unabhängig vom Status als Einreichenden und Beitragenden, die dann für alle gleichermaßen gelten würde. Dabei wäre eine niedrige Zahl problematisch wegen der oben angesprochenen Folgeprobleme. Mit drei bis fünf würde aber dem kollaborativen Charakter des Feldes Rechnung getragen und zugleich trotzdem ein sinnvolles Limit für die Zahl der Einreichungen gesetzt werden.
- Eine Maximalzahl pro Beitragsstyp. Z.B. ein Vortrag, zwei Poster, ein Panel, ein Workshop.
- Eine Differenzierung nach Beteiligungsstatus. Z.B. nach der Regel “nur einmal als Haupt-Einreichende auftreten, ansonsten aber beliebig viele Beteiligungen”. Ähnlich wäre ein Verfahren, das den Status “vortragende/r AutorIn” berücksichtigt. Diese Markierung wird z.B. bei der internationalen DH-Konferenz genutzt. Und auch hier könnte man sagen “nur ein/zwei Vorträge aber beliebig viele (oder maximal X) Beteiligungen”.
Wo kommen die AutorInnen her? Um an genaue Zahlen zu kommen, müsste man die zugeordneten Organisationen auswerten, was relativ aufwändig wäre. Einen unscharfen ersten Eindruck können bei aller Vorsicht auch die eMail-Adressen vermitteln. Dabei sind jenseits der klaren Länderkennungen nur noch die unspezifischen Domains aufzulösen (edu, net, org, com, eu), für die hier stillschweigend die Personen anhand ihrer Institutionen den jeweiligen Länder(gruppen) zugeordnet sind.
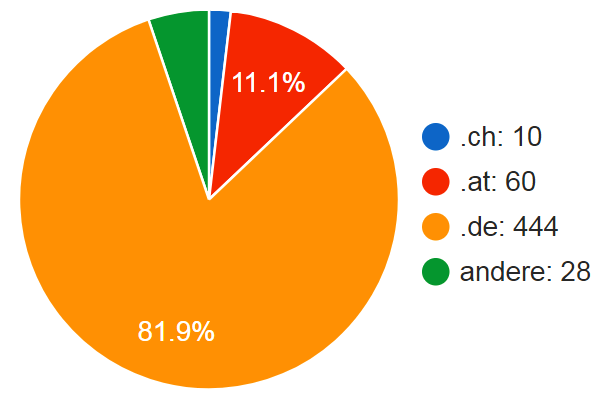
Abbildung 5: AutorInnen nach Ländern
Auffällig ist hier die enorme Unterrepräsentanz der Schweiz. Diese war aber auch schon für die Tagung 2016 in Leipzig von José Calvo Tello festgestellt worden. Rechnet man auf Einwohnerzahlen um, dann ergeben sich für die Länder 6,8 (AT) bzw. 5,4 (DE) bzw. 1,2 (CH) Beiträge je einer Million Einwohner.
Geht man weiter auf die geografische Verteilung der AutorInnen ein, dann zeigen sich gewisse lokale Zentren in den Digital Humanities. Es gibt 18 Orte[1] mit mehr als zehn “Beiträgen” in dem Sinne, dass alle AutorInnen aller Beiträge berücksichtigt sind. Das führt natürlich auch dazu, dass einzelne Personen mehrfach gezählt werden, was aber beabsichtigt ist, da es hier nicht so sehr um Personen als vielmehr den Gesamtbeitrag von “Orten” geht.
| Köln | 58 | Göttingen | 23 | Dresden | 13 | ||
| Berlin | 39 | Paderborn | 20 | Frankfurt | 13 | ||
| Würzburg | 37 | Mainz | 19 | Tübingen | 13 | ||
| Wien | 33 | Potsdam | 17 | Graz | 12 | ||
| Stuttgart | 32 | Leipzig | 17 | Moskau | 12 | ||
| Hamburg | 24 | Passau | 15 | Nürnberg | 12 |
Tabelle 2: Beiträge nach Orten
Eine gewisse Schieflage könnte man konstatieren, wenn man feststellt, dass aus diesen 18 Orten bereits 409 Beiträge kommen, während aus den weiteren 49 Städten nur 145 stammen. Das bedeutet: aus 27% der Orte kommen 74% der Beiträge. Oder, um leichter vergleichbare Zahlen zu nennen: aus rund 10% der Orte kommen 44% der Beiträge. Die Aussagekraft der Städteliste mag man relativieren, wenn man daran denkt, dass es Beiträge mit zehn oder elf AutorInnen gibt – so dass man schon mit nur zwei entsprechenden Postern oder Panels zu den Top-Ten-Städten gehören könnte.
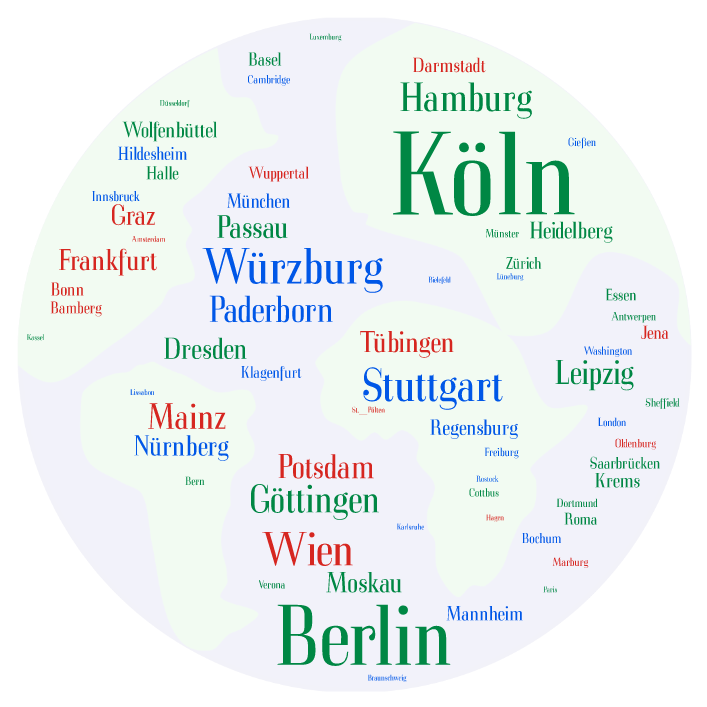
Abbildung 6: Beitragsorte, erstellt mit WordArt (https://tagul.com)
Interessant wäre eine Untersuchung der Geschlechter. Dies ist allerdings kaum möglich, da nur für die Einreicher das Geschlecht über die eingetragene Anrede bekannt ist. Es ist aber weder davon auszugehen, dass die Einreicher repräsentativ für die Gesamtmenge der Beiträger sind, noch dass sie eine besondere Gruppe bilden würden. Wir können (auch wegen der oben angesprochenen Frage der Mehrfacheinreichungen) außerdem nicht davon ausgehen, dass die Einreicher immer auch die HauptautorInnen eines Beitrages wären. Nennen kann man die Zahlen aber trotzdem: ziemlich genau ein Drittel (61) der Beiträge ist von Frauen eingereicht worden, die anderen zwei Drittel (126) von Männern.
Ähnlich sieht es für das Alter der Beitragenden aus. Auch hier ist die Datengrundlage zu dürftig, um zu belastbaren Aussagen zu kommen. Nur für 92 Personen ist im Konferenzsystem ein Geburtsjahr erfasst. Über die Repräsentativität können wir nichts sagen. Dass für diese 92 ein erstaunlich niedriges Durchschnittsalter von 40 Jahren zu ermitteln ist, kann deshalb bis auf weiteres nicht mehr als eine Randbemerkung sein.
Für die soziologische Struktur des Feldes wäre ansonsten noch der akademische Status interessant. Auch hier ist es aber leider so, dass viele Beitragende ihre Titel, also Dr. oder Prof., nicht angeben und die Datengrundlage deshalb unzuverlässig ist. Dabei würden sich u.a. neben den allgemeinen Quoten auch diese beiden Abgleiche für eine Untersuchung anbieten:
- Welche ProfessorInnen, die in der Liste der DH-Professuren seit 2008 erfasst sind, beteiligen sich an der Jahrestagung des DH-Verbandes?
- Welche Dominationen haben die Lehrstühle der übrigen beitragenden ProfessorInnen?
Dahinter steckt eine der Fragen nach Selbstverständnis und Formierung der Digital Humanities: Verstehen sich Inhaber von “Professuren für DH” (in dem weiten Sinne der o.g. Liste) dann auch wirklich als Teil jener DH-Community, die sich auf der Jahrestagung des Verbandes trifft? Und anders herum: welche ProfessorInnen auf “normalen” Lehrstühlen beteiligen sich an den DH? Welche Fächer sind hier vertreten?
Von den 33 ProfessorInnen auf der o.g. Liste haben 14 (42%) eingereicht, 19 haben sich nicht aktiv beteiligt. Nun müsste man vielleicht noch die Teilnehmerdaten abwarten um zu sehen, wie hoch der Identifikationsgrad und wie die Überschneidung von “DH-Professuren in einem recht weiten Verständnis” und “der zentrale Kongress des Faches” ist. Bei einer ersten Sichtung der Beiträger lassen sich mindestens 32 weitere ProfessorInnen identifizieren, die entweder für DH stehen (ohne auf der o.g. Liste aufzutauchen) oder aus den verschiedensten Fächern kommen. Hier fallen besonders die Informatik sowie die verschiedenen Sprach- und Literaturwissenschaften in’s Auge. Zu den geringer vertretenen Gebieten gehören noch die Geschichte, Kunstgeschichte oder Archäologie. Weitere sind ganz vereinzelt.
AutorInnennetzwerke
AutorInnen reichen gemeinsam ein und sie reichen – trotz der offiziellen Ein-Beitrag-Politik – mehrfach ein. Dadurch ergeben sich EinreicherInnennetzwerke, die sich visualisieren lassen:

Abbildung 7: EinreicherInnennetzwerke
In der Grafik sind Einzeleinreichungen ausgeblendet. Die Farben der Knoten stehen für verschiedene Orte. Die Positionierung der Knoten ergibt sich zufällig aus dem Visualisierungsalgorithmus für das Netzwerk.[2]
Jenseits der durch Teameinreichungen bedingten Gruppierungen erkennt man einige größere Netze, die durch Mehrfachbeteiligungen einzelner Personen entstehen. Durch die Farbcodierung lässt sich ein Eindruck davon gewinnen, ob Einreichungen bzw. Projektteams und Netze von Einreichungen eher lokal oder ortsübergreifend sind. Insgesamt halten wir die Aussagekraft dieser Netzwerkvisualisierung jedoch für sehr gering. Netzwerke entstehen vor allem auch durch die Zufälligkeit der Beteiligung oder Nicht-Beteiligung einzelner Personen an einem oder mehreren Beiträgen und der Zufälligkeit der Einreichung- oder Nicht-Einreichung von Beiträgen für eine Konferenz. Trotzdem ist es verführerisch, einzelne Netze genauer zu betrachten und für sinnvoll zu halten, weil sie durchaus reale Verbindungen wiedergeben.
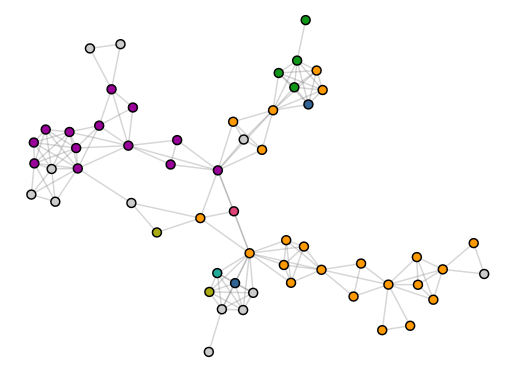
Abbildung 8: Ein Teilnetz
Abbildung 8 zeigt eines der größeren Netze mit Beiträgen vor allem aus Würzburg (blau) und Köln (gelb), das zufällig durch ein Panel zusammengehalten wird, an dem TeilnehmerInnen aus verschiedenen Orten beteiligt sind.
Themen
Der Call for Papers für die DHd2018 rief insbesondere zu Einreichungen auf, die sich mit Fragen der Kritik beschäftigen: Kritik der Digitalisierung, digitaler Angebote, Projekte und Werkzeuge, der digitalen Methoden, Methoden der digitalen Geisteswissenschaften, digitaler Wissenstheorie und digitaler Gesellschaft sowie zu allgemeinen Themen der DH. Zu welchen Themen sind nun tatsächlich Beiträge eingereicht worden?
Die AutorInnen hatten im Conftool an zwei Stellen die Möglichkeit, die in der Einreichung behandelten Themen durch Metadaten zu beschreiben. Eine Möglichkeit bestand darin, freie Schlagwörter (“Keywords”) zu vergeben, die zweite darin, bis zu sechs Themen aus einem kontrollierten Vokabular (“Topics”) auszuwählen.
Keywords
Für die Ermittlung der Zahlen zu den frei vergebenen Schlagwörtern wurden diese hier in Kleinschreibung überführt und der Weißraum (evtl. zusätzliche Leerzeichen) normalisiert. Insgesamt wurden 763 Schlagwörter vergeben – davon 578 verschiedene!
Überhaupt kommen nur sieben Schlagwörter fünfmal oder häufiger vor, so dass selbst die “prominentesten” Begriffe nur für marginale Teile der Beitragsmenge stehen:
| Schlagwort | # | Anteil |
| Annotation | 12 | 6,4 |
| TEI | 10 | 5,3 |
| Digitalisierung | 8 | 4,3 |
| Digitale Edition | 6 | 3,2 |
| Ontologie | 6 | 3,2 |
| Visualisierung | 5 | 2,7 |
| Kritik | 5 | 2,7 |
Tabelle 3: Schlagwörter nach Häufigkeit
Die Schlagwörter haben auf den ersten statistischen Blick nur eine geringe Aussagekraft, da kaum gemeinsame Stichworte vergeben wurden. Man könnte noch versuchen, durch Vereinheitlichung und Gruppierung Stichwörter zusammenzuführen (z. B. durch die Übersetzung fremdsprachiger Begriffe oder die Verbindung von Ober- und Unterbegriffen). Bei einer ersten Sichtung war unser Eindruck aber, dass sich nicht ohne weiteres thematische Korrelationen aufdrängen, so dass sich auch dadurch kein klareres Bild ergeben würde.
Abb. 9 zeigt eine Wordcloud der Keywords, bei der die Größenverhältnisse auf den Häufigkeiten der Vergabe basieren. Für die Wordcloud wurden die Wörter nicht in Kleinschreibung überführt.
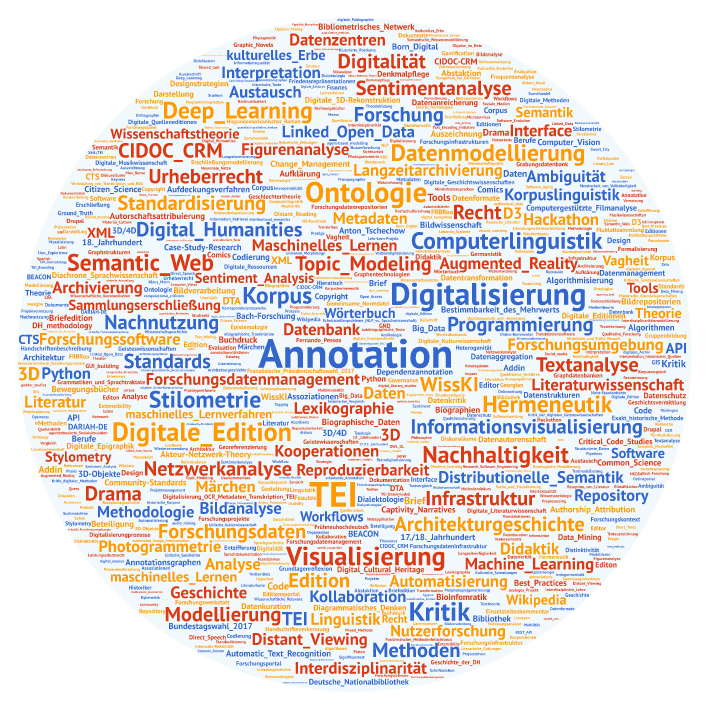
Abbildung 9: Wordcloud der frei vergebenen Schlagwörter (keywords), erstellt mit WordArt (https://tagul.com)
Insgesamt ist unser Eindruck, dass die freie Verschlagwortung für zahlenbasierte Auswertungen wenig Nutzen bringt, da offenkundig keine “gemeinsamen” Begriffe verwendet werden und sich dadurch keine Themencluster bilden, keine Felder oder Strukturen zu erkennen sind und über die Zeit auch keine Tendenzen beobachtbar werden können.
Topics
Das kontrollierte Vokabular, das im Conftool für die Vergabe von Topics zur Verfügung stand, wurde aus der Taxonomy of Digital Research Activities in the Humanities (TaDiRAH) abgeleitet. TaDiRAH unterscheidet zunächst die drei Bereiche “Research Activities”, “Research Objects” und “Research Techniques”. Für die ersten beiden Bereiche liegen mit “Aktivitäten” und “Objekte” Übersetzungen ins Deutsche vor, welche in das Conftool eingegangen sind. Allerdings kommt es dabei zu einer gewissen Verschiebung der Hierarchien. In TaDiRAH gibt es bei den Aktivitäten Untergruppen, die dann wiederum die Begriffe für die einzelnen Aktivitäten enthalten. Bei den Objekten ist dies nicht so, es werden direkt die einzelnen Objekte genannt. Auf das Conftool übertragen standen die einzelnen Objekte in einer Gruppe “Objekte” direkt neben den Aktivitäten, die zu Aktivitätengruppen (“Erfassen”, “Analysieren”, usw.) zusammengefasst waren. Es standen sich also nicht die Bereiche “Objekte” vs. “Aktivitäten” direkt gegenüber, sondern die Bereiche “Objekte”, “Erfassen”, “Analysieren”, usw. Man wählt deshalb zwischen den Begriffen in den Aktivitäten-Bereichen “Erfassen”, “Erzeugung”, “Anreichern”, “Analysieren”, “Interpretation”, “Aufbewahren”, “Veröffentlichen” und “Rahmenaktivitäten” und dann aus den Objekt-Begriffen aus. Wir können nicht abschätzen, ob den Einreichenden die grundlegende Zweiteilung in Aktivitäten und Objekte bewusst gewesen ist, möglicherweise spielt das für die Analyse aber auch keine große Rolle. Wir haben dennoch versucht, diese Unterscheidung bei der Auswertung zu berücksichtigen.
Insgesamt standen 75 Begriffe zur Auswahl. 35 in Objekten und 40 in den acht Aktivitäten-Gruppen. Der Begriff “Visualisierung” kommt in beiden Bereichen und damit doppelt vor, was für die Auswertung problematisch ist: Im Ergebnis ist nicht zu unterscheiden, ob dieses Schlagwort als Objekt oder Aktivität ausgewählt wurde.
Für die 187 Einreichungen wurden 976 Themen-Schlagwörter vergeben, also rund fünf Topics pro Beitrag. Von den 75 verfügbaren Begriffen sind 74 verschiedene tatsächlich verwendet worden. Nur “Curricula” wurde keinem Beitrag zugeordnet. Uns erstaunt, dass die Bandbreite der Topics fast vollständig ausgeschöpft wurde. Lediglich fünf der Topics wurden nur ein einziges Mal vergeben (“Übersetzung”, “Datei”, “Schreiben”, “Notenblätter”, “Crowdsourcing”). Es zeigt sich so, dass die DHd-Konferenz die Forschungsaktivitäten und Beschäftigung mit Forschungsobjekten in den digitalen Geisteswissenschaften in ihrer Breite abbildet – zumindest so, wie sie in TaDiRAH beschrieben werden und zumindest zum Zeitpunkt der Einreichungen.
Die Top Ten der Topics sind:
| Topic | Häufigkeit |
| Modellierung | 60 |
| Text | 50 |
| Annotieren | 48 |
| Inhaltsanalyse | 44 |
| Visualisierung | 37 |
| Methoden | 33 |
| Theoretisierung | 29 |
| Programmierung | 26 |
| Forschungsprozess | 26 |
| Kollaboration | 25 |
Tabelle 4: Topics nach Häufigkeit
Interessant ist die Frage, ob das Tagungsmotto Einfluss auf die Themenwahl hatte (Modellierung? Theoretisierung? Forschungsprozess?). Dazu müssten aber wohl die Vergabe der Topics in den Vorjahren zum Vergleich herangezogen werden. Dann könnte auch untersucht werden, ob es unabhängig vom Tagungsthema Entwicklungen bei den Topics gab.
In Abb. 10 sind die Topics als Wordcloud dargestellt. Wie bei den Keywords ist die Grundlage für die Wortgröße auch hier die Häufigkeit der Vergabe des Topics. Auch an den Wordclouds wird sichtbar, dass die Vergabe von Themen-Schlagwörtern aus dem kontrollierten Vokabular wie erwartet zu einer stärkeren Konzentration auf einzelne Begriffe führt, aber auch, wie die Verschlagwortung dadurch geleitet wird. Da TaDiRAH auf Aktivitäten und Objekte abzielt und auf eine allgemeinere Ebene der Betrachtung, ist ein Schlagwort wie TEI, das einen konkreten Datenstandard bezeichnet und bei der freien Vergabe häufig war, hier gar nicht mehr enthalten. Auf der anderen Seite ist “Text”, auf Platz zwei der Topics, bei den Keywords in der allgemeinen Form gar nicht vergeben worden, sondern nur spezifischer (z. B. “Liedtexte”, ”Nicht-Standardtexte”, “Short Texts”).

Abbildung 10: Wordcloud der vergebenen Topics, erstellt mit WordArt (https://tagul.com)
Wir können nun fragen, wie die Topics innerhalb der beiden Großgruppen vergeben wurden. Die Verteilung der Topics auf die einzelnen Aktivitätengruppen ist wie folgt:
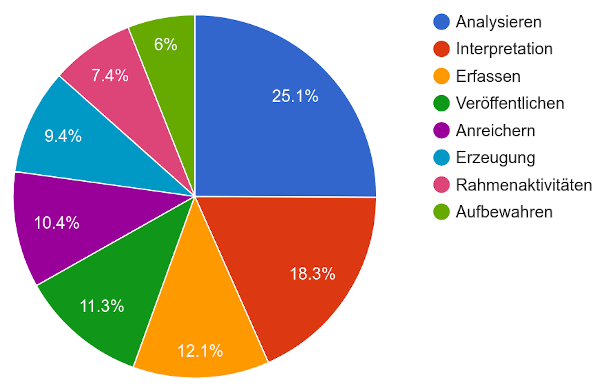
Abbildung 11: Topic-Vergabe nach Aktivitätengruppen
Abb. 11 zeigt, dass alle Aktivitätengruppen vertreten sind. Analyse und Interpretation sind häufiger vergeben als die anderen, dominieren aber nicht die Gesamtheit der vergebenen Schlagwörter.
Will man eine Grundunterscheidung zwischen Daten erzeugenden und Daten auswertenden Aktivitäten machen, dann haben für das Erstere Erfassen, Erzeugen und Anreichern ein Gewicht von 31,9% und für das Letztere Interpretation und Analyse ein Gewicht von 43,4 Prozent. Der Zweischritt, Daten zu erstellen und dann auszuwerten, steht damit für drei Viertel der Aktivitäten. Hinzu kommen Aktivitäten jenseits der Auswertung, zu denen Veröffentlichen und Aufbewahren gehören. Diese machen nur 17,3 % aus.
Auch hier wäre die Frage, ob das Tagungsthema der “Kritik” die Bereiche der Datenerzeugung und -auswertung begünstigt hat. Entsprechend müsste dann ein Topic wie “Aufbewahren” bei der DHd2017 in Bern, wo das Thema “Nachhaltigkeit” hieß, ein höheres Aufkommen gehabt haben.
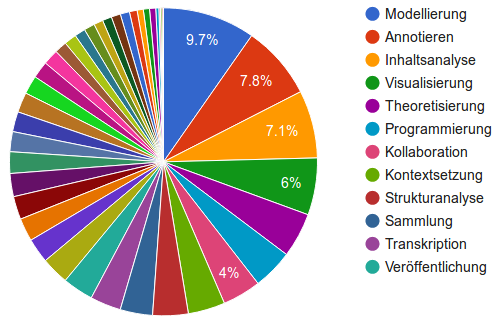
Abbildung 12: Topic-Vergabe nach Aktivitäten
Bei den Einzeltopics in den Aktivitäten selbst liegen mit Modellierung, Annotieren, Inhaltsanalyse, Visualisierung und Theoretisierung ebenfalls Begriffe vorne, denen man immerhin eine gewisse Nähe zum Fokus “Kritik” unterstellen könnte. Insgesamt sieht man hier aber eine relativ gleichmäßige Verteilung über zahlreiche prominente Topics hinweg (siehe Abb. 12).
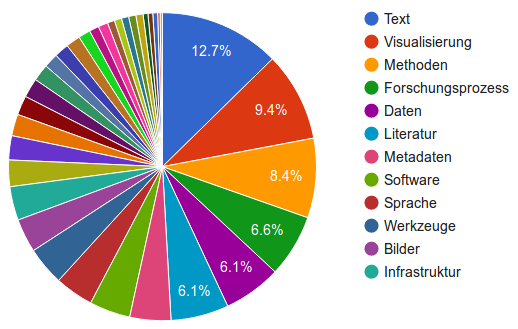
Abbildung 13: Topic-Vergabe “Objekte”
Wie zu erwarten führt bei den Objekten der “Text” die Liste der häufig vergebenen Stichworte an (siehe Abb. 13). Im Sinne der Taxonomie müsste “Visualisierung” hier als Forschungsobjekt gemeint sein, die Beiträge also Visualisierungen untersuchen (nicht verwenden). Darüber, in welchem Sinn die vorgegebenen Themen-Schlagwörter tatsächlich eingesetzt worden sind, kann man nur spekulieren. Gerade bei den Visualisierungen scheint es verwunderlich, dass diese als Objekt so weit oben rangieren. Durch die Unklarheit, ob das Topic tatsächlich als Objekt oder als Aktivität ausgewählt wurde, kann der Wert von 9,4 % aber nicht vergleichend gedeutet werden. Zusätzlich haben sie noch Auswirkungen auf die anderen Zahlen, so dass auch deren Deutung problematisch ist.
TaDiRAH hat einen sehr weiten, differenzierten, um nicht zu sagen diffusen Objektbegriff. In einem engeren Verständnis primärer Objekte als Gegenstände digitaler Forschung würde man vielleicht eher eine Gruppe wie Text, materielles Objekt, Bild, Sprache, Notenblätter, Audio etc. erwarten. Darin würde die Dominanz von “Text” gegenüber “Bild” und den anderen genannten Objekttypen noch deutlicher sichtbar werden. Die folgende Tabelle zeigt für einige Objekt-Topics (im engeren Sinne), bei wie vielen Beiträgen sie vergeben wurden:
| Topic |
# Beiträge (absolut) |
# Beiträge (relativ) |
| Text | 50 | 27 % |
| Literatur | 24 | 13 % |
| Sprache | 16 | 9 % |
| Bilder | 14 | 8 % |
| Manuskript | 8 | 4 % |
| Artefakte | 7 | 4 % |
| Ton | 3 | 2 % |
| Notenblätter | 1 | 0,5 % |
Tabelle 5: Beiträge mit ausgewählten Objekt-Topics
Die Quantifizierung der Topic-Zuordnungen ist nur ein Weg, diese auszuwerten. Interessant kann es darüber hinaus sein zu untersuchen, welche Themen miteinander verbunden sind. TaDiRAH gibt eine Gruppierung vor, aber bei der Vergabe der einzelnen Topics können diese von den Einreichenden frei kombiniert werden.
Für die Vergabe der Topics bei den einzelnen Beiträgen liegt die Frage nahe, ob es Korrelationen zwischen Schlagwörtern bzw. Schlagwortgruppen gibt. Dies sei hier am Beispiel der Aktivitätengruppen untersucht. Als gemeinsames Vorkommen wurde gewertet, wenn mindestens ein Schlagwort aus der Aktivitätengruppe mit einem anderen Schlagwort aus einer anderen Gruppe kombiniert wurde. In der ersten Zeile von Tab. 6 ist die Gesamtzahl der Beiträge angegeben, die Schlagwörter aus der jeweiligen Aktivitätengruppe haben (z. B. haben 64 Beiträge Schlagwörter aus der Gruppe “Erfassen”). Im mittleren Tabellenbereich ist für jede Aktivitätengruppe ermittelt worden, wie viel Prozent der Beiträge, die Schlagwörter aus der Gruppe haben, auch Schlagwörter aus einer anderen Gruppe tragen (z. B. haben 41 % der Beiträge, die mit Schlagwörtern aus der Gruppe “Erfassen” versehen sind, zugleich auch Schlagwörter aus der Gruppe “Erzeugen”). Die letzte Tabellenzeile schließlich gibt den Kombinationsfaktor an: Mit wie vielen Schlagwörtern aus anderen Aktivitätengruppen sind die Beiträge ausgehend von der ersten Aktivitätengruppe im Durchschnitt kombiniert (z. B. sind die Beiträge mit Schlagwörtern aus der Gruppe “Erfassen” im Durchschnitt mit 2,4 Schlagwörtern aus anderen Gruppen kombiniert)?
| Erf. | Erz. | Anr. | Ana. | Int. | Aufb. | Veröff. | Rahm. | |
|
64 |
52 | 56 | 99 | 89 | 28 | 56 | 38 | Gesamtzahl |
|
– |
50 % | 46 % | 33 % | 27 % | 43 % | 34 % |
29 % |
Erfassen |
|
41 % |
– | 23 % | 27 % | 20 % | 32 % | 32 % |
26 % |
Erzeugen |
|
41 % |
25 % | – | 29 % | 26 % | 25 % | 32 % |
18 % |
Anreichern |
|
52 % |
52 % | 52 % | – | 58 % | 14 % | 27 % |
34 % |
Analysieren |
|
38 % |
35 % | 41 % | 52 % | – | 18 % | 36 % |
50 % |
Interpretieren |
|
19 % |
17 % | 13 % | 4 % | 6 % | – | 29 % |
11 % |
Aufbewahren |
|
30 % |
35 % | 32 % | 15 % | 22 % | 57 % | – |
47 % |
Veröffentlichen |
|
17 % |
19 % | 13 % | 13 % | 21 % | 14 % | 32 % |
– |
Rahmenaktivitäten |
| 2,4 | 2,3 | 2,2 | 1,7 | 1,8 | 2,0 | 2,2 |
2,2 |
Kombinationsfaktor |
Tabelle 6: Kombinationen von Aktivitätengruppen
Tabelle 6 zeigt, dass Beiträge, die Schlagwörter aus den Gruppen Analysieren oder Interpretieren haben, in geringerem Maße mit Schlagwörtern aus anderen Gruppen kombiniert worden sind als ausgehend von den übrigen Gruppen. Die höchsten Kombinationswerte werden erreicht für Interpretieren-Analysieren (58 %), Aufbewahren-Veröffentlichen (57 %), Erfassen-Analysieren (52 %), Erzeugen-Analysieren (52%) und Anreichern-Analysieren (52%).
Auch für die Topics im Einzelnen lässt sich fragen: Welche Topics stehen über ihr gemeinsames Vorkommen bei den Beiträgen in Beziehung zueinander?
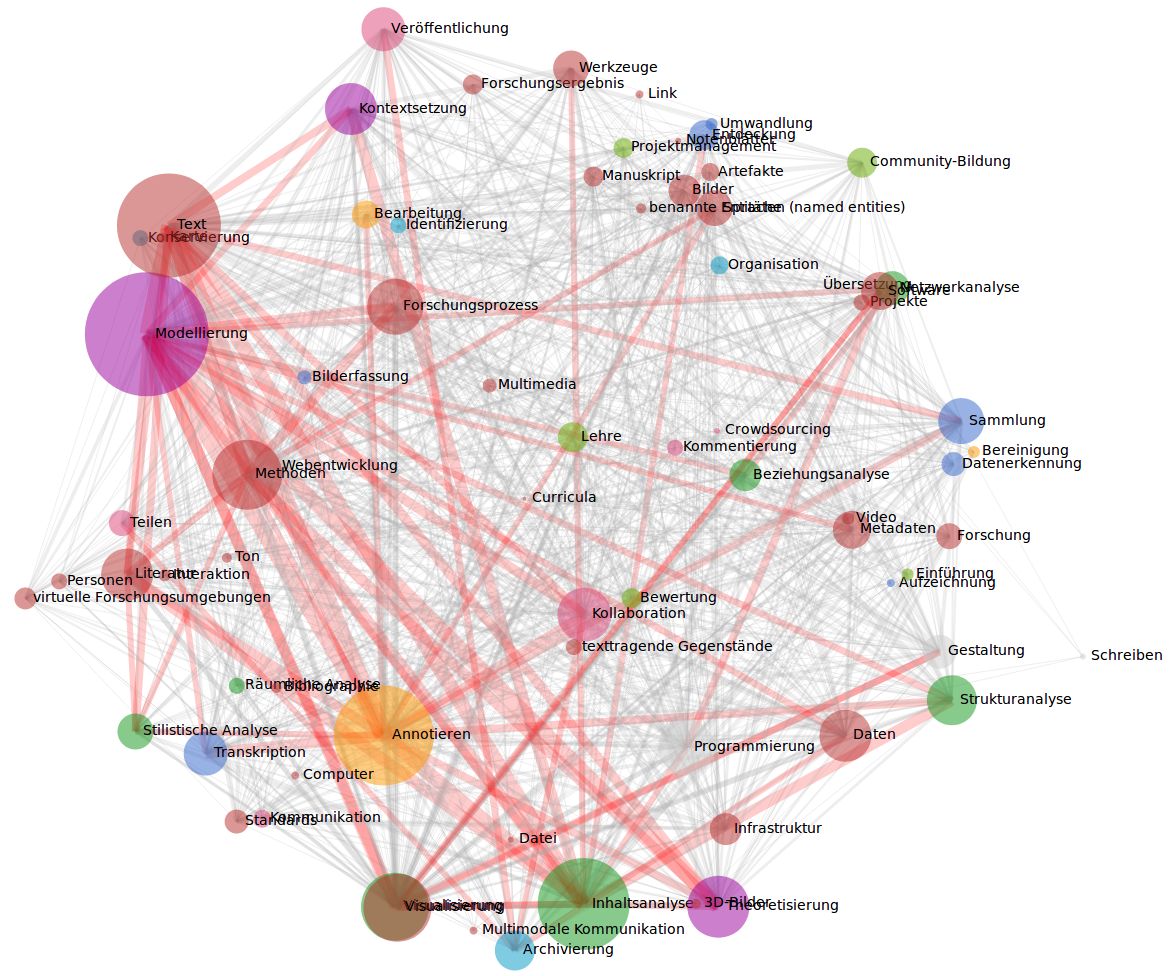
Abbildung 14: Netzwerk der Topics, die bei Einreichungen zusammen vergeben wurden
Topics, die bei den Einreichungen zusammen vergeben wurden, sind in Abb. 14 als Netzwerk visualisiert (erstellt mit D3). Jeder Knoten repräsentiert ein Topic. Die Größe der Knoten spiegelt die Häufigkeit der Vergabe des Topics wider, die Farbe der Knoten bildet die Zugehörigkeit zur Oberkategorie in TaDiRAH ab (Objekte: blau, Aktivitäten: gelb-orange-grün). Die Dicke der Verbindungen zwischen den Knoten zeigen an, wie häufig die Topics gemeinsam vergeben wurden. Verbindungen, die häufiger als fünfmal vorkommen, sind rot eingefärbt. Die Gestalt des Netzwerks zeigt, dass die Topics untereinander auf vielfältige Weise verbunden sind. Die stärkste Verbindung besteht mit 19 Vorkommen zwischen “Annotieren” und “Text”, gefolgt von “Annotieren” und “Modellierung” mit 16 Vorkommen. Die folgende Tabelle zeigt die Top Neun der gemeinsam vorkommenden Topics (den zehnten Platz teilen sich sieben Kombinationen mit je elf Vorkommen, die hier nicht mehr aufgenommen sind):
| Häufigkeit | Topics |
| 19 | Annotieren – Text |
| 16 | Annotieren – Modellierung |
| 15 | Inhaltsanalyse – Text |
| 15 | Modellierung – Theoretisierung |
| 15 | Modellierung – Text |
| 14 | Annotieren – Inhaltsanalyse |
| 13 | Inhaltsanalyse – Modellierung |
| 12 | Inhaltsanalyse – Literatur |
| 12 | Methoden – Text |
Tabelle 7: Häufigkeiten von Topic-Kombinationen
Fazit
Abschließend bleibt festzuhalten, dass unsere Auswertung der Daten zu den DHd2018-Einreichungen einen eher explorativen Charakter hat. Dabei hat sich gezeigt, dass es einen gewissen Widerspruch zwischen vielleicht naheliegenden Fragestellungen und den verfügbaren Daten gibt. In vielen Fällen lassen sich Fragen zur Struktur und Entwicklung der Digital Humanities mit den vorliegenden Informationen kaum beantworten. Auf der anderen Seite führen manche Daten auch nicht zu klaren Bildern, aus denen sich Aussagen ableiten lassen würden.
Dies liegt auch daran, dass die Daten im Conftool ganz bestimmte Funktionen (nämlich eine Tagung zu organisieren) erfüllen und nicht danach organisiert sind, ausgewertet zu werden. Ein Beispiel dafür sind die Anredeformen: Sie haben vor allem die Funktion, in Serienbriefen eingesetzt werden zu können – eine belastbare Untersuchung der Geschlechterverteilung wird dadurch leider nicht ermöglicht.
Prinzipiell denkbar wäre es auch gewesen, Text-Mining-Methoden auf die Abstracts anzuwenden, um z. B. Themen genauer zu untersuchen. Jedoch stehen auch dafür keine geeigneten Daten zur Verfügung, weil die Kurzabstracts im Conftool nicht immer vorhanden sind oder sehr unterschiedliche Längen haben. Auch hier ist zu konstatieren, dass es kein einheitliches Verständnis von der Verwendung des Feldes “Kurzabstract” bei den Einreichenden gegeben hat. Hier könnte bei den kommenden Tagungen vielleicht für mehr Klarheit gesorgt werden.
Interessant in Bezug auf den Stand und die Entwicklung des Feldes “Digital Humanities” werden solche Auswertungen eigentlich erst durch den Vergleich mit Auswertungen zu anderen Tagungen oder für dieselbe Tagung über die Zeit. Wir hoffen, einen weiteren Baustein dafür geliefert zu haben.
[1] Die Orte als Orte der angegebenen Affiliationen sind nicht ganz einfach zu ermitteln. Wir haben dazu eine Positivliste erstellt, mussten dabei aber auch etliche Institutionsangaben berücksichtigen, die gar keinen Ort enthielten – … liebe Wiener … . [2] Die Visualisierung basiert auf einer Vorlage von Mike Bostock, bei der die Bibliothek D3 eingesetzt wurde.
Einreichungen zur DHd 2019 | DHd-Blog
[…] Conftool, über das alle Einreichungen angemeldet wurden. Der Beitrag orientiert sich an dem Blogeintrag von Ulrike Henny-Krahmer und Prof. Dr. Sahle aus dem letzten Jahr, welche die Daten der DHd 2018 ausgewertet […]
Einreichungen zur DHd 2019 – II | DHd-Blog
[…] letztjährigen Blog-Eintrag von Ulrike Henny-Krahmer (Würzburg) und Patrick Sahle (Köln) zeigte sich, dass sich auf der DHd in Köln nicht alle an diese Vorgaben gehalten hatten auch wenn […]
Wo ist die Schweiz? | DHd-Blog
[…] nun beobachten die statistischen Auswertungen der DHd-Tagung eine Unterrepräsentation der Schweiz. Henny-Krahmer und Sahle stellten im Nachgang zur DHd 2018 […]