Vom #vDHd2021-Workshop zum #GraphPub-Workingpaper
Einleitung
Digitale Publikationen und Graphentechnologien haben ihre experimentellen Phasen mittlerweile verlassen und Eingang in den DH-Kanon gefunden. Beide Bereiche weisen eine große Menge an Forschungsliteratur, Leitlinien, Standards und Anwendungsfällen auf. Im Kontext des digitalen Publizierens ist der Einsatz von Graphentechnologien jedoch noch nicht etabliert. Etliche Beispiele zeigen das Potential auf, das der Einsatz von Graphentechnologien im Rahmen des digitalen Publizierens entfalten kann (vgl. etwa den Open Knowledge Research Graph (TIB): https://www.orkg.org/orkg/ oder semantisch angereicherte Publikationen: http://scihi.org/). Zwar besteht ein großes Interesse in der DH-Community am Einsatz von Graphentechnologien im Kontext digitaler Publikationen, es mangelt aber an niedrigschwelligen Einstiegs- und Orientierungsmöglichkeiten. Aus diesem Grund veranstalteten die DHd-AGs „Digitales Publizieren“ und „Graphen und Netzwerke“ im April 2021 einen gemeinsamen Workshop im Rahmen der vDHd2021.
Der Workshop nahm sich dem Thema aus drei Perspektiven an: (1) die angereicherte Publikation, (2) die Modellierung von Aussagen im Text und (3) die Publikation von Graphen als Graphen.
Einführungspräsentation: https://docs.google.com/presentation/d/1laEzqsADrl0jDmVcY-G0UwkjucgR70yZzPw2GUzkkBs/edit#slide=id.p2
Fokusgruppe 1: Angereicherte Publikation – Die digitale Publikation als Wissensgraph
Ausgehend von den unterschiedlichen Publikationstypen (z.B. Paper, Bilddaten, Blogs und Datenbanken) wurden Elemente identifiziert, die im Rahmen einer Aufwertung von digitalen Publikationen mit Graphtechnologien angereicht werden könnten. Dabei wurden auch die Risiken einer automatischen Anreicherung diskutiert. Darauf aufbauend wurden best practice Beispiele (siehe Jamboard) identifiziert, welche den Mehrwert von Anreicherung deutlich machten. In einem nächsten Block wurden die bereits vorhandenen sowie die gewünschten Funktionalitäten bei digitalen Publikationen herausgearbeitet. Ein weiterer Themenblock, der von Florian Thiery mit einem Impulsreferat begonnen wurde, thematisierte das Nutzen von Linked-Open-Data. Hier wurden LOD-Ressourcen und konkrete Anwendungsszenarien diskutiert. Ein Realitycheck hinsichtlich der Umsetzung von angereicherten digitalen Publikationen rundete die Themengruppe ab. Zusammenfassend kann festgehalten werden, dass die Anwendungsszenarien für LOD stark vom Publikationstyp abhängig sind. Die Arbeit im Workshop zeigte aber auch deutlich, dass Potenziale vorhanden, aber interdisziplinäre Austauschmöglichkeiten dringend nötig sind.
Das Jamboard der Fokusgruppe 1 findet sich hier; Folien zum Vortrag „Linked Open Data in Action!“ von Florian Thiery könnt ihr euch hier anschauen.
Fokusgruppe 2: Modellierung von Aussagen im Text
Einführend wurden verschiedene Motivationen und Perspektiven der Aussagenmodellierung thematisiert und vier Achsen differenziert. Drei ‚Pitches‘ dienten als Impulse für den Austausch: 1. (Stand-Off-)Annotationen und Verankerung von Aussagen im Text, 2. Extraktion von Aussagen aus Text, 3. Aussagen als statements in Wikibase. Die engagierte Diskussion betraf die mit der Modellierung von Aussagen verbundenen sozialen Prozesse (z.B interdisziplinäre Erstellung von Thesauri oder Normdaten), methodische Fragen (wie das Verhältnis von textimmanenten Informationen und Domänenwissen) sowie Aspekte der Datenmodellierung (u.a. Möglichkeiten der Nachnutzung sowie zugleich die Spezifik geisteswissenschaftlicher Aussagen im Hinblick auf mehrstellige Relationen und Reifizierung). Es ging um einen Austausch darüber, was schon realisiert wurde oder mittelfristig realisierbar erscheint (konkrete Werkzeuge, Ansätze und Vorhaben), sowie um längerfristige Perspektiven und Visionen (bezogen auf das Publikationswesen sowie im Hinblick auf Recherchemöglichkeiten, Bedarfe der Community, Forschungs- und Tool-Desiderate), aber auch Grenzen, bisherige Hürden sowie kritische Perspektiven.
Einführungsfolien und Folien zu den ‘Pitches’ können hier, weitere Materialien hier eingesehen werden. Das Jamboard der Gruppe findet ihr hier:

Fokusgruppe 3: Publikation von Graphen als Graphen
In Fokusgruppe 3 (einführende Folien hier) haben wir vor allem festgestellt, dass man aus zwei Perspektiven über die Thematik der Graphpublikation diskutieren kann: von der technischen Perspektive der Datenpublikation als Backend-Infrastruktur oder aus Sicht der Visualisierung von Graphdaten etwa als Netzwerke im Frontend. Je nachdem aus welcher Sicht man die Thematik betrachtet, setzt man entweder data literacy oder visual literacy bei den Rezipient:innen voraus. Die Zielgruppe sollte in jedem Fall vor der Publikation klar umrissen werden. Weitere Themen, die diskutiert wurden, waren etwa Möglichkeiten der Versionierung und wissenschaftlichen Referenzierbarkeit konkreter Zustände z.B. in interaktiven Visualisierungen von Graphen. Auch in Fokusgruppen 3 entstand ein Jamboard:
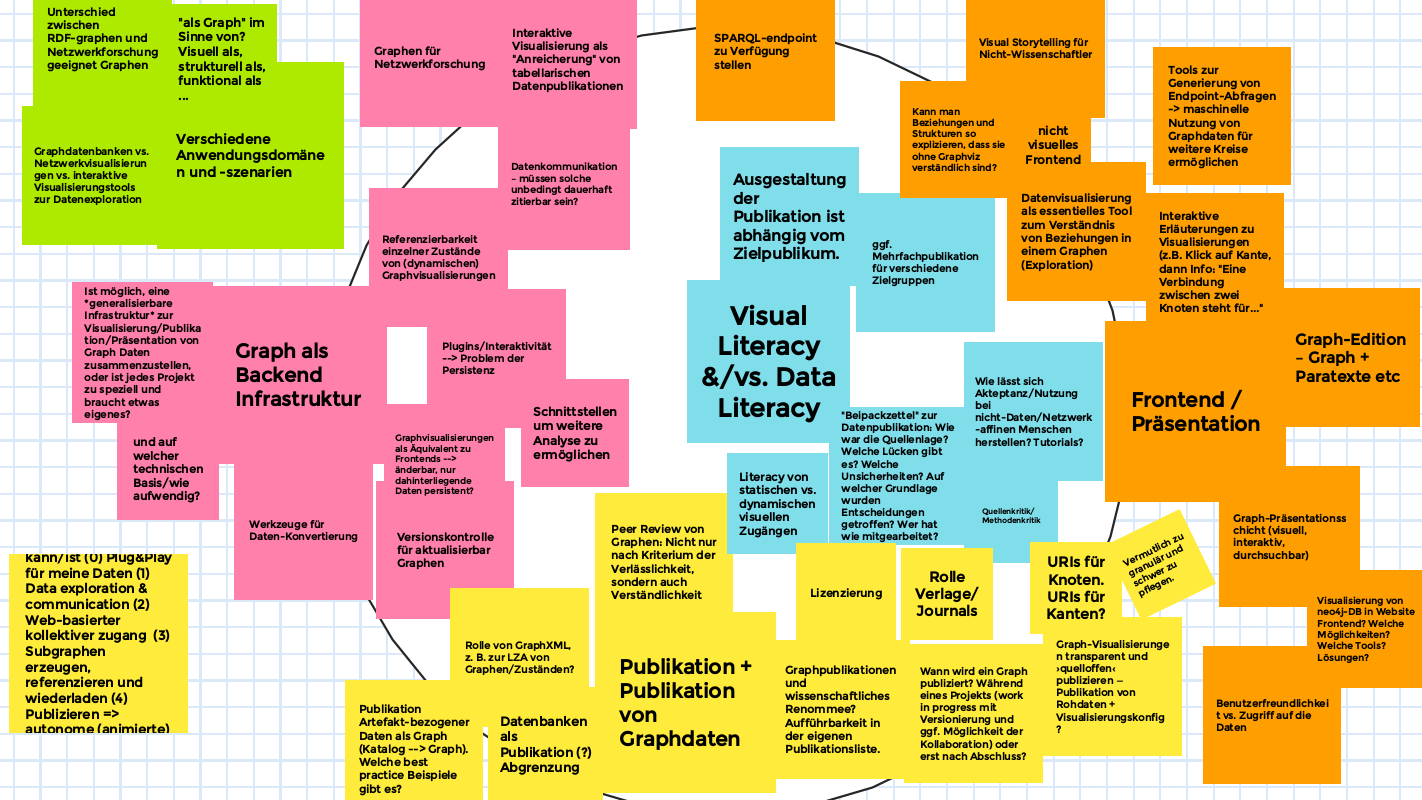
Weitere Links aus der Session
- Karten und Konjunkturgraphen zu Sandra Richters Buchprojekt Eine Weltgeschichte der deutschsprachigen Literatur: http://www.germanliteratureglobal.com/index.php/Karten_und_Konjunkturgraphen_zu_%C3%9Cbersetzungen_deutschsprachiger_Literatur
- Japanese Virtual Media Graph: https://jvmg.iuk.hdm-stuttgart.de/
- Ressourcenliste “Legal Theory Graph Project” https://pad.gwdg.de/eQtgt_J6SxiWArOjQXT20w?view
- Beispiele für die Publikation von Netzwerkdaten:
- Interaktive Publikation mit Geodaten – “The Chinese Deathscape. Grave Reform in Modern China”: https://chinesedeathscape.supdigital.org/read/when-the-dead-go-marching-in
- HNR bibliography – Interactive Graph Exploration: http://historicalnetworkresearch.org/bibliography/#Interactive%20Graph%20Exploration
Nachlese
- Blogbeitrag Zoltán Kacsuk: https://jvmg.iuk.hdm-stuttgart.de/2021/04/13/taking-part-in-the-pimp-your-publication-workshop/
Ausblick und Aufruf
Der Workshop zeigte sowohl die Potentiale von graphbasierten Publikationen wie auch den Bedarf nach einer tiefergehenden Beschäftigung auf. Aus diesem Grund soll ein kollaborativ erstelltes Workingpaper angegangen werden. Das Workingpaper entsteht in Zusammenarbeit der DHd-AGs „Digitales Publizieren“ und „Graphen und Netzwerke“, aber alle anderen Interessierten können ebenfalls teilnehmen. Ein kurzes erstes Abstimmungstreffen findet am 17. September um 14 Uhr unter https://webconf.tu-bs.de/tim-2ku-nmg statt. Kommt gerne vorbei!
Weitere Informationen findet ihr auf diesen Seiten:
- AG Graphen & Netzwerke: https://graphentechnologien.hypotheses.org/
- AG Digitales Publizieren: https://dig-hum.de/ag-digitales-publizieren
- Bibliographie und Zotero-Gruppe der AG Graphen & Netzwerke: https://graphentechnologien.hypotheses.org/bibliographie
- Zeitschrift für digitale Geisteswissenschaften (ZfdG): https://zfdg.de
- Working paper der AG Digitales Publizieren: DOI: 10.17175/wp_2021_001
- Invite link Discord: https://discord.gg/vQT3Fc6GFY
- Twitter: #GraphPub
Blogbeitrag von: Aline Deike, Thomas Efer, Maria Hinzmann, Jan Horstmann, Julian Jarosch & Timo Steyer
Kommentar schreiben