Workshop “Metadaten Analysieren” der DHd-AG Zeitungen & Zeitschriften
von Nanette Rißler-Pipka, Harald Lordick und Torsten Roeder
Während viele Millionen Zeitungs- und Zeitschriftenseiten in Portalen wie Europeana oder der Deutschen Digitalen Bibliothek am Bildschirm lesbar sind, steht maschinenlesbarer Text nur in kleinen Mengen der Forschung zur Verfügung. Schade, denkt man: Damit kann man ja nur begrenzt etwas anfangen. Doch all diese Digitalisate sind katalogisiert und manchmal sogar zu einem Anteil bis auf die Inhaltsverzeichnisse jeder Ausgabe, also bis auf Artikelebene erfasst. Für Zeitungen und Zeitschriften sind diese zusätzlichen Informationen schon durch die Struktur des Mediums besonders reichhaltig und wichtig.
Diese Informationen nennen wir “Metadaten”.[1] Und es ist gut, dass es sie gibt: Sie verraten uns zum einen in systematischer Form das, was aus den Digitalisaten explizit hervorgeht, wie etwa den Namen der Zeitung/Zeitschrift, den Druckort, das Erscheinungsdatum. Zum anderen enthalten sie beispielsweise auch die Regelmäßigkeit des Erscheinens, die Anzahl der gescannten und der gedruckten Exemplare, die Autorinnen und Autoren sowie weitere Akteure, die Anzahl der Seiten und der Artikel oder die Sprache, in der die Artikel verfasst wurden. All dies kann viel Recherche erfordern. Speziellere Metadaten wie beispielsweise die Anzahl der Werbeanzeigen, das Geschlecht der Autorinnen und Autoren, die Anzahl der Bilder, Überschriften und Kunstwerke sind vielleicht auch gar nicht erfasst oder erfordern weitergehende Recherche. Dennoch: Was könnte man mit diesen Metadaten alles anfangen, welche Forschungsfragen behandeln? Und: Wie kommt man an diese Metadaten systematisch heran? Wie wertet man sie maschinell aus? Damit beschäftigte sich der Workshop der DHd-AG Zeitungen & Zeitschriften, welcher den Auftakt zu einer kleinen Reihe von Veranstaltungen zum wissenschaftlichen Arbeiten mit historischen digitalen Periodika bildete.
Im Vorfeld
Wir haben alle Interessierten bei Anmeldung zum Workshop darum gebeten, ihre Forschungsfragen anzugeben. Dabei kam bereits eine große Vielfalt zusammen: von der Untersuchung der Akteure in bestimmten Zeitschriftentiteln bis hin zu in Zeit, Raum und Genre begrenzten Suchanfragen, um zunächst einmal das relevante Korpus festzulegen. Die Komplexität der faszinierenden Forschungsfragen ließ aber auch im Vorfeld bereits erkennen, dass wir vor allem grundlegende Werkzeuge mitgeben können, nicht aber im Workshop selbst zur Beantwortung gelangen würden. Intensive Hands-On-Passagen gaben jedoch Gelegenheit, bereits im Rahmen des Workshops Einzelfragen in kleinen Gruppen zu besprechen.
Bei der Vorbereitung beschäftigte uns natürlich auch die Frage, wie man bei mehr als zwanzig Teilnehmenden eine selbsterklärende und funktionierende Python-Umgebung einrichten kann. Am Ende stand allen Teilnehmenden ein individuelles, cloudbasiertes Jupyter-Notebook zur Verfügung, in dem Code-Blöcke durch ein Schritt-für-Schritt-Tutorial erklärt wurden und auch gleich durch praktische Programmierung ausprobiert werden konnten. Dadurch konnten wir fast unmittelbar nach der Vorstellungsrunde mit dem Coden beginnen.
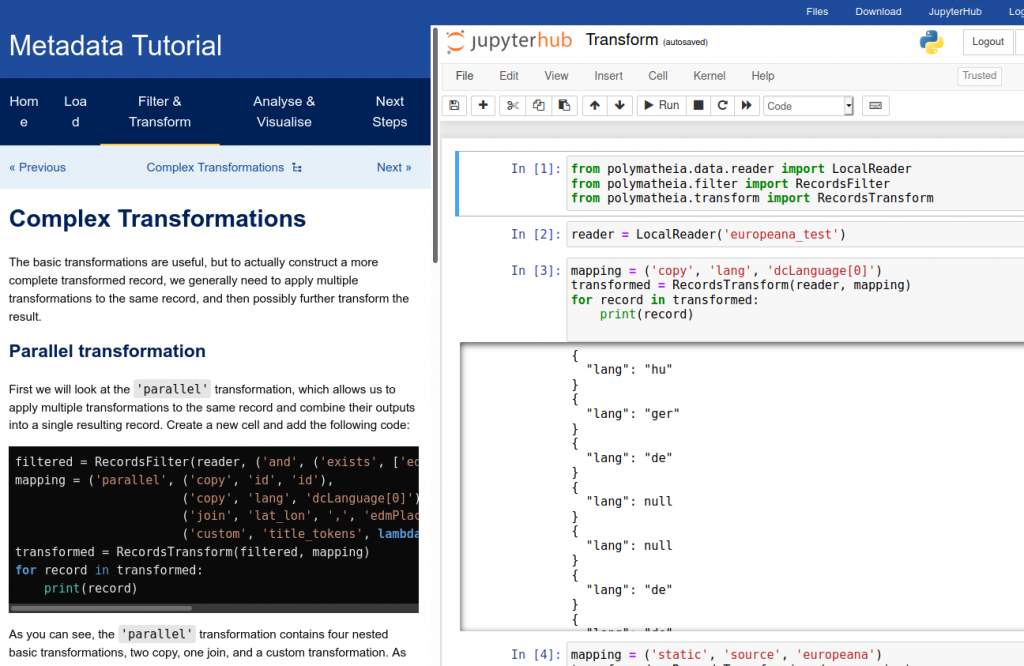
(Tutorial: Mark Hall, Andreas Lüschow)
Das Schritt-für-Schritt-Tutorial wurde von Mark Hall in Zusammenarbeit mit Andreas Lüschow verfasst und ermöglichte den Teilnehmenden, während des Workshops im integrierten Jupyter Notebook ‘mitzucoden’ und später auch eigene Abfragen in der Programmiersprache Python zu schreiben.
Erster Tag: Wie komme ich an Metadaten?
Schon die Frage der ersten Einheit: “Wie komme ich an Metadaten?” eröffnete neue Perspektiven. Es gibt zwei Wege, die man gehen kann, um an das gewünschte ‘Metadaten’-Korpus zu gelangen. Erstens, das manuelle Anlegen einer persönlichen Bibliographie (die zumeist aus Verweisen untereinander entsteht und mehr oder weniger kanonisch ist). Zweitens, das Verwenden einer vorliegenden Metadaten-Sammlung eines Daten- und Dienstanbieters. Hier ist man auf die vorgegebene Zusammensetzung der jeweiligen Sammlung beschränkt, hat dafür den Vorteil eines klaren Kriteriums der Auswahl. Vermutlich kann man sich auch auf einen gewissen Qualitätsstandard verlassen oder zumindest darauf hoffen. Im weiteren Verlauf des Workshops und der Analyse lernten wir, inwieweit man sich darauf verlassen kann: Wie alle Datensammlungen sind Metadaten niemals perfekt. Ein Beispiel ist die Landesangabe “mul”, die für “aus mehreren Ländern” steht und der Standarddefinition entspricht, aber für Außenstehende schwierig zu interpretieren ist. Auch wird wenig mit kontrollierten Vokabularen gearbeitet, die abweichende Mehrfachbezeichnungen vereinheitlichen könnten.
Wenn man Metadaten automatisiert beziehen möchte, braucht man eine Schnittstelle. Manchmal werden diese Schnittstellen zumindest für Metadaten auch frei und offen auf der Webseite des Anbieters genannt, wie in dem im Workshop gewählten Beispiel: https://www.digizeitschriften.de/kontakt/schnittstellen/. Oft sind Schnittstellen aber nicht offen sichtbar, sondern ihre Adressen müssen entweder erfragt werden oder stecken hinter einer Anmeldeschranke. Wer besonders genau hinschaut, kann Metadaten-Schnittstellen unter Umständen auch anhand der URL im DFG-Viewer erraten.
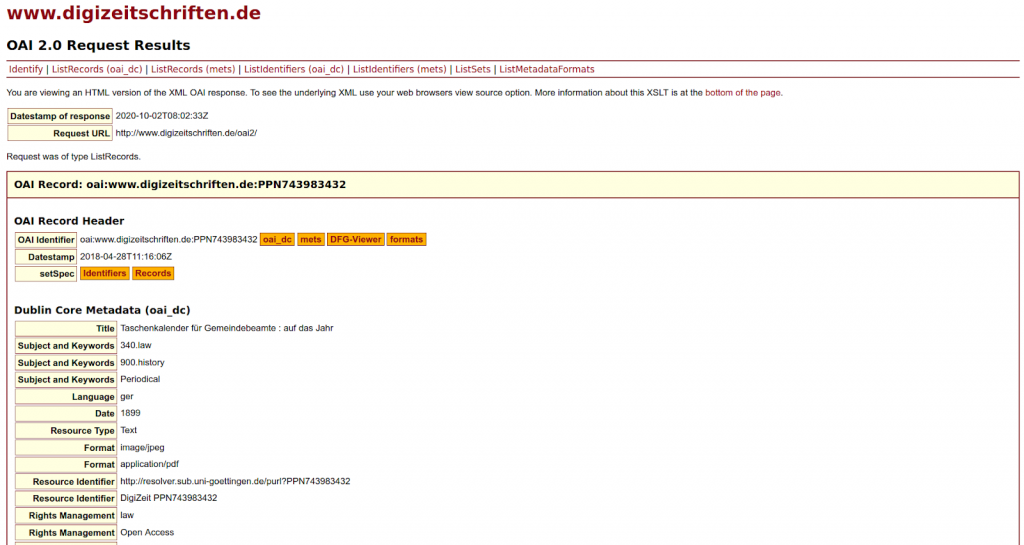
Nun sind Schnittstellen in der Regel nicht gleichbedeutend mit Download-Buttons. Gleichzeitig steht für den Einstieg oder sporadische Nutzung keine Software zur Verfügung, die niederschwellig das Harvesting von Metadaten z.B. via OAI-PMH-Schnittstelle erlauben würde. Manche Provider wie www.digizeitschriften.de bieten eine HTML-Ansicht ihrer OAI-PMH-XML-Ausgabe an. Dies ist überaus hilfreich, um das Datenangebot zunächst zu inspizieren: welche Metadatenformate, Datensets und Inhalte sind überhaupt verfügbar? Eine solche HTML-Ansicht erlaubt zwar prinzipiell auch die manuelle interaktive ‚Abfrage‘ der Schnittstelle. Für die meisten Anwendungsfälle in den Digital Humanities ist dies jedoch keine Option, und oft ist dieser ‚View‘ auch gar nicht verfügbar. Entsprechend sinnvoll ist die von Mark Hall aus Anlass des Workshops neu entwickelte Python-Bibliothek “Polymatheia” (frei verfügbar unter https://polymatheia.readthedocs.io). Diese kapselt die Komplexität der Interaktion mit den Metadatenschnittstellen (unter anderem werden OAI-PMH, Europeana, und demnächst auch Search/Retrieve via URL unterstützt) und bietet Funktionalität zum Filtern und Transformieren der Metadaten. Die Metadaten können dann als JSON, XML, CSV, oder nach Pandas exportiert werden und stehen für die weitere Analyse bereit.
Zweiter Tag: Wie analysiere und visualisiere ich Metadaten?
Am darauffolgenden Tag wurde ausführlich über statistische Verfahren und Visualisierungen gesprochen. Statistisches Grundlagenwissen ist enorm wichtig, wenn man aus den zahlreichen Metadatensätzen – die leicht in die Tausende und auch Hunderttausende gehen können – Korrelationen zwischen Datenparametern wissenschaftlich fundiert nachweisen möchte. Visualisierungen können indessen ein sehr hilfreiches Mittel sein, um einen Überblick über ein (Meta)daten-Korpus zu gewinnen oder bestimmte Charakteristika auszumachen, helfen aber wiederum wenig als Aussagewert.
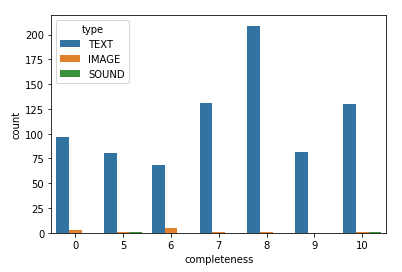
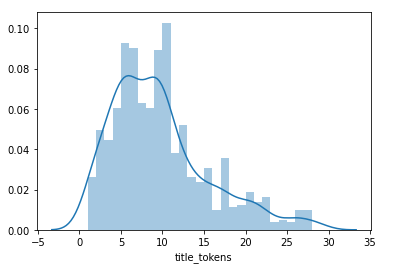
In mehreren Breakout-Rooms (mit Big Blue Button sehr flexibel handhabbar) organisierten sich dann spontan verschiedene Gruppen nach Interessenlage: Ein Raum beschäftigte sich mit der Struktur des METS/MODS Metadatenschemas, während in einem anderen die Metadaten der Leopoldina-Zeitschrift “Miscellanea Curiosa” über eine OAI-PMH-Schnittstelle geharvestet sowie ein intensiverer Blick auf die Metadaten der “STURM”-Edition (AdW Mainz) geworfen wurde; in einem weiteren Raum wurde diskutiert, wie spezifische Fragestellungen gelöst werden könnten. Eine Hilfe- und Selbsthilfegruppe für alle technischen Belange bildete sich in einem vierten Raum. Die Zeit in den Breakout-Rooms war hilfreich, um das Erlernte in der Praxis zu erproben und zu vertiefen, reichte aber absehbar nicht aus, um wissenschaftliche Ergebnisse hervorzubringen.
Damit wären wir wieder bei den ursprünglichen Fragestellungen der Teilnehmenden angekommen: Nachdem allen nun eine Art universeller Handwerkskasten zur Verfügung steht (nebenbei haben wir praktisch sogar ein wenig Python gelernt!), geht es im Nachgang des Workshops an die wissenschaftliche Anwendung. Wichtiger als schnelle Antworten auf einzelne Fragestellungen erschien uns als Ergebnis der neue Blick auf Metadaten: Sie bilden ein vielfältiges Universum, dem man mit einigen Kniffen Geheimnisse entlocken kann, welche bei ihrer Erstellung im Einzelfall noch nicht erahnbar waren.
Fazit
Natürlich war der Workshop vor der Pandemie noch als Präsenzveranstaltung geplant und wir haben uns bewusst entschlossen, die im Vergleich intensive Vorarbeit (welchen virtuellen Raum, aber auch welche Lösung für das Tutorial?) zu investieren. Zwar mussten wir auch bei der virtuellen Veranstaltung die Teilnehmerzahl beschränken, um Hands-On-Sessions zu ermöglichen, dafür aber erhöht sich die Nachnutzbarkeit: Denn die Videos stehen fortan als Online-Tutorial zur Verfügung. Ferner besteht die Möglichkeit, bei entsprechendem Interesse den Workshop zu wiederholen.
Gerade weil sich sehr viele Menschen außerhalb der DHd-AG Zeitungen & Zeitschriften angemeldet haben, fehlte uns sehr die Möglichkeit, sich in der Pause oder beim gemeinsamen Abendessen näher kennen zu lernen, weiter über die individuellen Forschungsfragen zu fachsimpeln und das “Socialising” generell. Natürlich bevorzugte man in der Pause lieber einen Spaziergang in der realen Welt gegenüber Tele-Smalltalk am Bildschirm. Nichtsdestotrotz konnte die DHd-AG im Nachgang einen Mitgliederzuwachs verzeichnen – weitere sind immer willkommen (https://dhd-ag-zz.github.io/).
Es steht nun die Anwendung des “Handwerkskastens” im eigenen Projekt noch aus. Erst dort werden sich die Tücken der großen Metadatensammlungen, die Inkonsistenzen und auch die Lücken im Gedächtnis zeigen: Wie konnte man in Python nochmal nach den drei Autorennamen im Metadaten-Set filtern? Umso besser, dass es nicht nur das nachlesbare Tutorial (https://github.com/mmh352/metadata-tutorial), sondern auch die Anleitung zur Einrichtung eines ‘baugleichen’ Jupyter-Notebooks auf dem heimischen Gerät und ohne Cloudlösung gibt.
Willkommener Nebeneffekt eines solchen Workshops nach unserem Eindruck: Das gemeinsame Wissen über verfügbare Metadatenangebote wächst. Es lohnt sich außerdem, Datenanbieter im Vorfeld hinsichtlich Verfügbarkeit oder Details anzusprechen, zumal dies die Nachfrage seitens der Community betont und damit wiederum – zumindest perspektivisch – weitere Angebote fördert.
Alle Infos zum Workshop können hier abgerufen werden:
https://dhd-ag-zz.github.io/workshops/2020-09_metadata_analysis
[1] Zur allgemeinen Definition von Metadaten: “Perhaps a more useful, ‘big picture’ way of thinking about metadata is as the sum total of what one can say about any information object at any level of aggregation.” (Anne J. Gilliland: “Setting the Stage”, in: Baca, Murtha, Hrsg. Introduction to Metadata. Third edition. Los Angeles: The Getty Research Institute, 2008/2016, p. 2. https://www.getty.edu/publications/intrometadata/setting-the-stage/)
RaDiHum20 spricht mit der AG Zeitungen und Zeitschriften - RaDiHum 20
[…] Der Workshop wird 2021 im Rahmen der virtuell stattfindenden vDHd nochmal angeboten. Inhaltlich wird es auch wieder darum gehen einen ganzen Workflow abzubilden: Angefangen von der Beschaffung der Metadaten, über Strukturen und Datenformate, statistische Auswertungen anhand bestimmter Kriterien bis hin zu Fragestellungen an die Daten mit Python, Visualisierung und Interpretation der Erkenntnisse. Eine Nachbetrachtung zum Workshop findet ihr auch auf dem DHd-Blog. […]
Metadaten-Workshop der AG Zeitungen & Zeitschriften: Zur zweiten Auflage – vDHd2021 – Experimente
[…] veranstalten durften. Ein ganz ähnlicher Workshop fand bereits im September 2020 statt (hier dazu ein Bericht), den wir nun aufgrund des großen Interesses im Rahmen der vDHd ein zweites Mal aufgelegt […]