Archiv nach Kategorie: ‘Forschung (Methode)’
179 Posts; Seite 11
Hypermediale Sprachauskunftssysteme sind logisch strukturierte Informationsangebote im Internet, mit deren Hilfe sich Fakten und Zusammenhänge über natürliche Sprache zunächst speichern und anschließend einem breiten Nutzerkreis zur Verfügung stellen lassen. Eine wesentliche Motivation entspringt der Vision von einem zentralen Informations-Repository, das digitale, hypertextuell oder in einer Datenbank organisierte Inhalte multifunktional nutzbar machen kann. Populär ist in […]
weiterlesen
2015 war im Bischöflichen Priesterseminar in Trier die Ausstellung Maschinen und Manuskripte – Digitale Erschließung der Handschriften von St. Matthias zu sehen, die aus dem Kooperationsprojekt eCodicology hervorgegangen war. Diese Ausstellung kann mittlerweile dauerhaft und kostenlos im Internet besucht werden. Das Kompetenzzentrum für elektronische Erschließungs- und Publikationsverfahren in den Geisteswissenschaften/Trier Center for Digital Humanites (TCDH) […]
weiterlesen
Die Abteilung Grammatik des Instituts für Deutsche Sprache (IDS) lädt ein zur zweiten Arbeitstagung ars grammatica, die mit dem Thema „Grammatische Terminologie – Inhalte und Methoden“ vom 8.-9. Juni 2017 am IDS in Mannheim stattfindet. In Form von Einzel- und Gemeinschaftsvorträgen, Posterständen, Systemdemonstrationen und Diskussionen sollen Fragestellungen diskutiert werden, die sich im Spannungsfeld zwischen inhaltlicher […]
weiterlesen

Das Institut für Dokumentologie und Editorik (IDE) bereitet derzeit eine Sonderausgabe des Rezensionsjournals RIDE zum Thema „Digital Text Collections“ vor und sucht RezensentInnen, die geisteswissenschaftliche digitale Textsammlungen für die Ausgabe besprechen möchten. RIDE ist eine Open Access Zeitschrift, die sich in mittlerweile fünf Ausgaben der Besprechung digitaler wissenschaftlicher Editionen widmet. Mit dem Sonderband zu „Digital […]
weiterlesen
Das Deutsche Literaturarchiv Marbach, die Klassik Stiftung Weimar und die Herzog August Bibliothek Wolfenbüttel erschließen mehr als ein halbes Jahrtausend deutscher und europäischer Kulturgeschichte. Um die bereits seit mehreren Jahren praktizierte Kooperation zu intensivieren, haben sich die drei Einrichtungen in einem vom Bundesministerium für Bildung und Forschung geförderten Forschungsverbund zusammengeschlossen. In dessen Rahmen werden drei […]
weiterlesen
Im Auftrag der Deutschen Forschungsgemeinschaft soll vom 9. bis 13. Oktober 2017 in der Villa Vigoni ein internationales literaturwissenschaftliches DFG-Symposion zum Thema „Digitale Literaturwissenschaft“ stattfinden. Es folgt organisatorisch dem Muster der Germanistischen Symposien der DFG, wie sie seit den 1970er Jahren durchgeführt wurden. Die Konferenzsprachen sind Englisch und Deutsch, wobei alle Teilnehmer in der Lage […]
weiterlesen
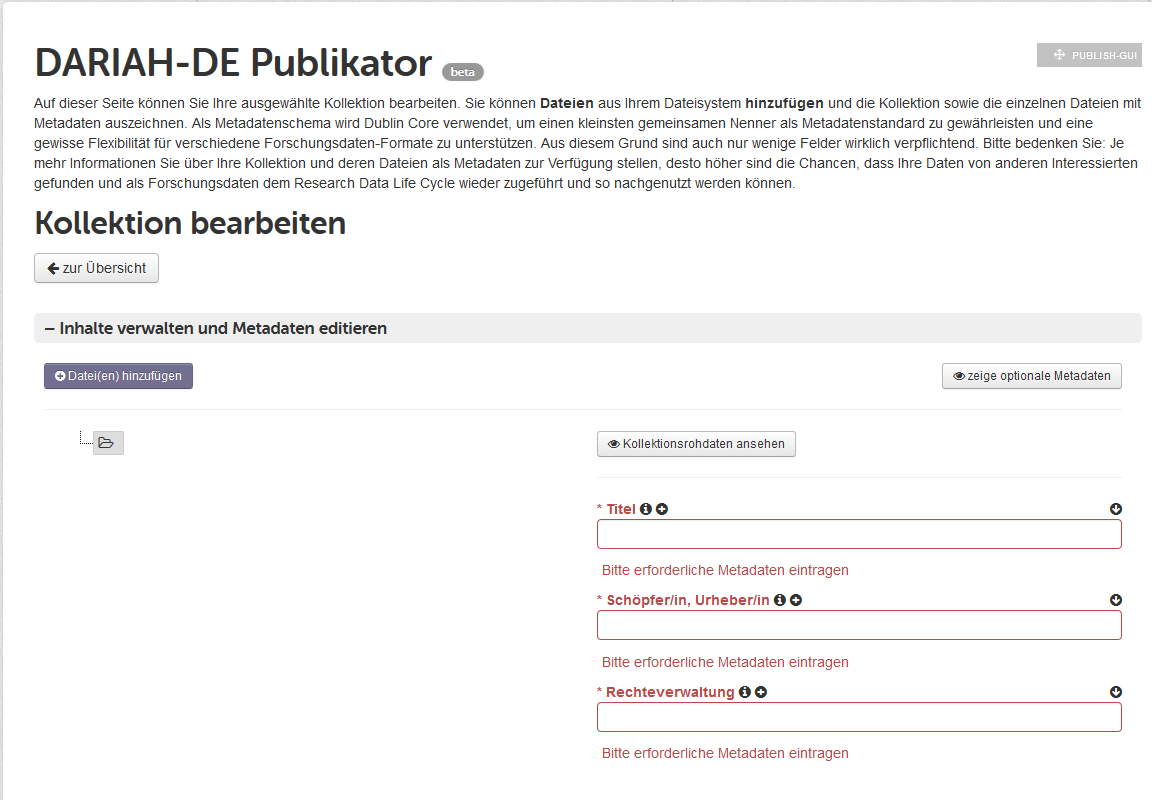
DARIAH-DE entwickelt ein Repositorium als digitales Langzeitarchiv für geistes- und kulturwissenschaftliche Forschungsdaten, das nun in einer fortgeschrittenen Betaversion vorliegt. Ihre Forschungsdaten können hier nachhaltig und sicher gespeichert, mit Metadaten versehen und veröffentlicht werden. Ihre Kollektion sowie jede einzelne Datei ist so langfristig verfügbar und erhält einen eindeutigen und dauerhaft gültigen persistenten Identifikator (PID), mit dem […]
weiterlesen
Als Masterstudentin der Computerlinguistik und Texttechnologie an der Justus-Liebig-Universität Gießen habe ich an der diesjährigen DHd-Tagung in Leipzig teilgenommen, die zum Thema „Modellierung – Vernetzung – Visualisierung: Die Digital Humanities als fächerübergreifendes Forschungsparadigma“ vom 7. bis 12. März 2016 über 460 Teilnehmer anzog. In diesem Beitrag möchte ich von meinen Eindrücken im Hinblick auf die Vortragsreihe „Vorträge_5b: […]
weiterlesen
Arthur Schopenhauer (1788‒1860) ist als Philosoph ein Begriff. Weniger bekannt ist hingegen, dass er auch Übersetzer war. So übertrug er u.a. das moralische Traktat Oráculo manual y arte de prudencia des spanischen Barockschriftstellers Baltasar Gracián (1601‒1658) ins Deutsche. Durch Schopenhauers Übersetzung wurde Graciáns Werk in Deutschland wieder bekannt und so verwundert es nicht, dass viele […]
weiterlesen
via Prof. Dr. Claudia Müller-Birn: Die seit Herbst 2015 laufende Umfrage „practices4humanities. Wissenschaftliche Forschungspraxis in den Geisteswissenschaften“ untersucht systematisch die aktuelle Forschungspraxis von Geisteswissenschaftlerinnen und Geisteswissenschaftlern aller Fächer und Disziplinen. Den Anfang der Befragung bildete die Region Berlin-Brandenburg, erste Ergebnisse finden sich im Sammelband „Digital Humanities in Berlin-Brandenburg“ des Einstein-Zirkels Digital Humanities. Die Umfrage wird […]
weiterlesen