Die Philosophie von Maß und Morphem – Fantastische Daten und wo sie zu finden sind
Ein Reisebericht der DHd 2026
Mit dem Bachelorzeugnis in der einen und der Zulassung zum Digital Humanities-Studium in der anderen Hand fühlte ich mich zu Beginn der DHd doch ein wenig wie Jacob Kowalski, als er das erste Mal mit der Welt der Zauberer und Hexen in Kontakt kam. Alles wirkte auf eigenartige Weise vertraut und doch – ja, wie sollte man es anders beschreiben – magisch.
Aus der englischen Linguistik kommend, trug ich einige Fragen mit in das erste Semester meines Masterstudiums. Eine davon drängte sich besonders in den Vordergrund: Wo stehen die Digital Humanities in einer Welt, in der doch Natur- und Geisteswissenschaften so klar und fein säuberlich getrennt scheinen? Es mag genau dieser Schein sein, der trügt. Gerade in der Sprachwissenschaft ist diese Linie noch mit Leichtigkeit wegzudenken. Doch wie könnte man überhaupt versuchen, das menschliche Verlangen nach Bedeutung von sich und der Welt, welches über Jahrhunderte in Bild und Schrift festgehalten wurde, mit reduktiven Ansätzen zu quantifizieren? Ein Algorithmus könnte doch unmöglich die irrationalen und subtilen Gefühls- und Denkweisen nachvollziehen, die uns Menschen so vertraut sind. Genau mit diesen Fragen beschäftigt sich der Essay „Meursault as a Data Point“ von Abhinav Pratap. Seine philosophische Sichtweise stimmte mich in den Tagen vor Beginn der DHd-Jahreskonferenz neugierig und offen dafür, als „Neuling“ in diesem Bereich meine eigene Meinung zu formen. Das majestätische Gebäude der Universität Wien begrüßte mich mit der Eleganz der Neurenaissance an jenem Montagmorgen. Passend zu dem Leitmotto der diesjährigen Konferenz dachte ich mir: „In jedem Text findet man Daten; doch gilt dies auch andersherum?“
Die Konferenz wurde in meinem Fall von Mark Hall von der The Open University (UK) mit seinem Workshop Arbeiten mit der μEdition eröffnet. In seiner dazugehörigen DHd-Publikation stellte er sich unter anderem die Frage: „[…] [W]ie viel Edition braucht eine Edition, um eine Edition zu sein?“ (Hall, 2026). Wir durften in dem Workshop ein praxisfähiges Tool mit Community-Zugang ausprobieren. Ich sah dies als eine angenehme Gegenbewegung zur totalen Datenlogik. Die μEdition arbeitet mit Blick auf pragmatische Produktions- und Publikationspfade, unter anderem mit statischen HTML-Ausgaben und niederschwelligen Wegen, um Editionen für Forschende zugänglich zu machen und den „Publikationsflow“ zu vereinfachen (Hall, 2026). Was in seinem Projekt ebenfalls eine große Rolle spielt, ist, dass nicht alles sofort auf maximale Komplexität ausgelegt sein muss. Vielmehr sollen Einstiege erleichtert werden und damit auch das Wachstum der jeweiligen Edition. Nicht nur Text bedeutet hier also Publizieren: Es geht auch darum, Editionen für alle zugänglich zu machen und dabei mit kleinen Ressourcen arbeitsfähig zu bleiben.
Als Sprachwissenschaftlerin stolperte ich in meinem Bachelorstudium nur selten über literaturwissenschaftliche Annotation. Umso erfrischender war für mich der Workshop, an dem ich am zweiten Tag der DHd teilnehmen durfte. Graphbasierte Text- und Wissensmodellierung mit dem ATAG-Editor und Entity-Manager wurde geleitet von Maximilian Michel, Sebastian Enns, Vincent Neeb und Andreas Kuczera von der Akademie der Wissenschaften und der Literatur Mainz sowie der Technischen Hochschule Mittelhessen. Komplementär zur μEdition adressiert ATAG die Frage, wie man Text so speichert bzw. modelliert, dass das Datenmodell dem editorischen Denken näherkommt. In der ersten Theoriephase wurden alle Teilnehmenden in die browserbasierten Tools, den ATAG-Editor und den Entity-Manager, eingeführt. In der Praxisphase wurde jedem von uns ein Text ausgeteilt, mit dem wir unseren eigenen Regest, aufgeteilt in Summary, Archival History und Commentary, erstellen durften. Anschließend wurde uns freigestellt, die Tools zu testen und „wild drauf los“ zu annotieren (je nach Vorliebe). Zum Schluss wurde uns die Verknüpfung unserer Texte, Annotationen und Entitäten in einem Netzwerk auf Basis von Labeled Property Graphs visualisiert. Ich empfand dieses Tool als wunderbare Möglichkeit für webbasierte und vor allem kollaborative Annotation und es hat mir persönlich gezeigt, dass Text nicht bloß einer Kategorie angehört, sondern auch eine Praktik selbst ist.
„Dinge sind […] nicht nur einfach wahrzunehmende „Gegenüber“, sondern sie konstruieren die Umwelt des Menschen und bestimmen die Möglichkeit seines Handelns.“ (Peter Hahn, Materielle Kultur, 2014, S. 31)
Sind Zeichnungen, Bilder, Gemälde und Abbildungen auch Dinge im Sinne des obigen Zitats? Der Vortragsblock zu Digital Art History zeigte mit sehr interessanten Anwendungspraktiken den „Zustand“ der Digital Humanities in Bezug auf die Analyse von historischen Bilderzählungen und mittelalterlichen Manuskripten bis hin zur Erkennung von Pflanzen in Herbarien und Drucken. In den Vorträgen wurde unter anderem gezeigt, wie schwer es ist, Figuren (z. B. Maria oder den Engel Gabriel in Verkündigungsszenen) zuverlässig über Stile hinweg zu erkennen. Es wurde argumentiert, dass unter anderem Gesichtsdaten für eine erfolgreiche Analyse nicht ausreichen und es an Kontext im Sinne von zugehörigem Körper und Umgebung bedarf, um die Erkennung zu verbessern. Die Kernfrage lautet hier: Was zählt als Signal und was als Rauschen, wenn Kunstwerke zu Datensätzen werden?
Auch die Automatisierung des Klassifikationssystems ICONCLASS wurde behandelt. Dieses wurde seit den 1940er-Jahren für Bildinhalte entwickelt und wird heute in vielen kulturellen Sammlungen zur inhaltlichen Erschließung verwendet (Thomas, n. d.). Da die manuelle Vergabe solcher Klassifizierungscodes aufwändig ist, nutzen neue Automatisierungsansätze multimodale Modelle, Vektorsuche und Retrieval-Augmented Generation (RAG), um Iconclass-Klassifikationen aus Bildbeschreibungen abzuleiten, und berichten teils deutlich bessere Ergebnisse als reine Keyword-Methoden (Thomas, n. d.).
Mit diesen Ansätzen werden Bilder zu:
- Daten (Computer Vision, Feature-Extraktion, Klassifikation)
- Bedeutung (ikonographische Kategorien)
- Interpretation (Ambiguität, Kontext, Fehlklassifikation)
Der damit erzeugte Modelloutput ist dabei nicht einfach Bedeutung, sondern eine konstruierte Leseart, die sehr produktiv sein kann, jedoch immer wieder neu interpretiert werden muss, um auf blinde Flecken aufmerksam zu werden.
Nach den wunderbaren Vorträgen habe ich am Donnerstag meine ganz persönliche Winkelgasse und damit auch mein Highlight der DHd gefunden: die Postersessions.
Umgeben zu sein von so vielen talentierten, motivierten Forschenden, die die verschiedensten Projekte vorstellen, ließ keinen Nischenwunsch offen. Ich hatte das Glück, drei Personen für ein kleines Interview zu gewinnen.
Anja Gerber von der Klassik Stiftung Weimar adressiert mit NFDI4Objects die Zusammenführung heterogener Daten zu materiellem Kulturerbe und nutzt dafür Anschluss an Modelle wie CIDOC CRM bzw. Crosswalk-Ontologien. Das von ihr vorgestellte Projekt ist ein schönes Beispiel für Daten als semantische Vermittlung zwischen den Communities der Archäologie, Museen, Restaurierung und Forschung.
Der Posterbeitrag von Nina Brolich von der Universität Erfurt beschäftigt sich mit der Frage: Welche Infrastrukturen zwingen uns zu bestimmten Fragestellungen? Und welche öffnen neue Alternativen? Mit ihrem Projekt Edge AI zeigt sie, dass sich Aufgaben in den DH wie Entity Recognition auch lokal und mobil auf Mikrocontrollern mit einfacher Netzwerkarchitektur lösen lassen – im Kontrast zu der Idee, dass alles über immer größere Rechenressourcen laufen müsse.
Schließlich hat mich Erik Radisch von der Sächsischen Akademie der Wissenschaften zu Leipzig in das Projekt eines 3D-Positionssystems für Zeichnungen und Bilder in den Höhlen von Kucha in Zentralasien eingeführt. Hierbei wird versucht, die Wandgemälde, die teils entfernt und in Museen gebracht wurden, zu dokumentieren und ihren ursprünglichen Standort zu rekonstruieren. Dabei adressiert er auch das Modellierungsdilemma, dass schematische Darstellungen Bereiche erzeugen können, die es so im Original nicht gibt, und dass man bei diesen Verzerrungen methodisch mitdenken muss. In jedem Fall war es eine tolle Erfahrung, in den Stand des Projekts mit der bereitgestellten VR-Brille einmal selbst eintauchen zu dürfen.
Ob Kaffeepause, Rathausempfang, Posterslam, Eröffnungsfeier oder Exkursion: Die DHd2026 war von der Einführungs- bis zur Abschlusskeynote eine wahrlich magische Erfahrung. Ein großes und von Herzen kommendes Dankeschön geht hierbei an CLARIAH-AT, die mir mit der Vergabe des Stipendiums einen großen Schritt in meine persönliche Entwicklung als Forscherin in den Digital Humanities und zugleich die Erfahrung einer wunderbaren und inspirierenden Community ermöglicht haben.
Für all die Workshops, Poster Sessions und Vorträge finden Sie, liebe Leserinnen und Leser, alle wissenschaftlichen Essays, Links und Nennungen sowie weiterführende Literatur am Ende dieser Seite. Gerade für diejenigen, die erst seit kurzem den Wind der DH in ihren Segeln spüren, kann ich nur wärmstens empfehlen, sich dieser Literatur zu widmen. Wer weiß, vielleicht erweitert sie auch Ihren Horizont und führt Sie auf ganz neue, unerwartete Gewässer.
Nun, von Harry Potter zur Seemannsweisheit – so richtig entscheiden konnte ich mich in meinen verwendeten Metaphern ja nicht. Und wie sieht es mit meinem anfänglichen Dilemma der DH und der vielen unbeantworteten Fragen aus? Geisteswissenschaften existieren nicht ohne die komplexen Fragen menschlicher Existenz. Informationswissenschaft wiederum arbeitet mit quantifizierbaren Strukturen, die Daten greifbar machen. Die Digital Humanities erscheinen mir deshalb weniger als Kompromiss zwischen beiden Welten, sondern eher als ein Raum der Symbiose; ein Ort, an dem Interpretation und Modellierung nebeneinander existieren können. Und vielleicht ist es genau diese dritte Instanz, die während der DHd am deutlichsten hervortrat: der Forschende selbst, der zwischen Daten und Bedeutung vermittelt und ihnen Bedeutung gibt.
Storymap und Netzwerkvisualisierung
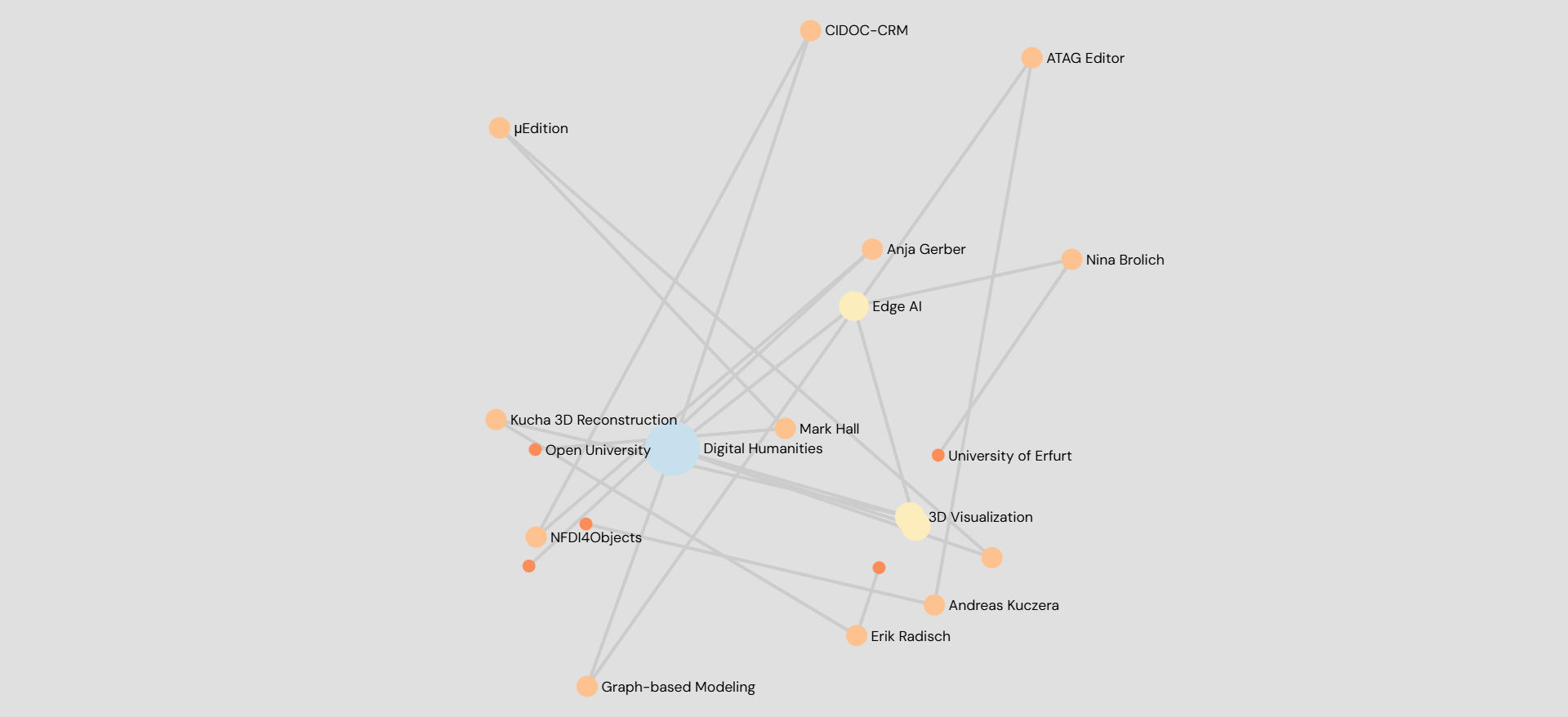
Um diese vielen Eindrücke, Projekte und Methoden nicht nur erzählerisch, sondern auch visuell darzustellen, habe ich im Anschluss an diesen Blogbeitrag eine kleine digitale Dokumentation erstellt. Eine StoryMap führt durch meine persönlichen Stationen der Konferenz, während eine Netzwerkvisualisierung die Verbindungen zwischen den erwähnten Projekten, Methoden und Forschenden veranschaulichen soll. Die Knoten der Netzwerkanalyse repräsentieren Forschende, Projekte, Institutionen und methodische Ansätze, während die Kanten ihre thematischen Verbindungen darstellen. Betrachtet man das Ergebnis, erkennt man, wie stark die Digital Humanities von interdisziplinären Verknüpfungen zwischen Edition, Kulturerbedaten, visueller Analyse und digitalen Modellierungsverfahren geprägt sind.
Beide Visualisierungsformen verstehen sich als Versuch, die verknüpften Wege der DHd auch mit Methoden aus dem eigenen Fachgebiet abzubilden – selbstverständlich völlig experimentell.
Literatur
Hall, M. (2024). Edition & niederschwellige digitale Editionen.
Kuczera, A. (2024). Applied Text as Graph: ATAG – Graphbasierte Text- und Wissensmodellierung.
Mandl, T. (2026). Plants in historical herbarium collections (DHd2026 Beitrag).
Pratap, A. (2025). Meursault as a Data Point. Essay.
Prathmesh M.., et al. (2020). Recognizing characters in art history using deep learning.
Thomas, D. B. (n.d.). Automating Iconclass: LLMs and RAG for large-scale classification of religious woodcuts.
Interviews
Brolich, N. (2026, 27. Februar). DH on the Edge [Poster session interview].
Gerber, A. (2026, 27. Februar). Vom Objekt zum Wissensnetz [Poster session interview].
Radisch, E. (2026, 27. Februar). 3D Positioning System for the Paintings in the Caves of Kucha [Poster session interview].
Verwendete Materialien
- DHd2026 Konferenzprogramm
- Poster Sessions
- Workshopmaterialien der Vortragenden
Weiterführende Literatur
De Boer, V., et al. (2024). Hybrid Intelligence for Digital Humanities.
Peck, E. (2019). Data is personal: Approaches to making data tangible. Linköping University.
Hullman, J. (2019). Why authors don’t visualize uncertainty. IEEE Transactions on Visualization and Computer Graphics.
Kommentar schreiben