Archiv nach Autor: ‘Stefan Dumont’
44 Posts; Seite 4
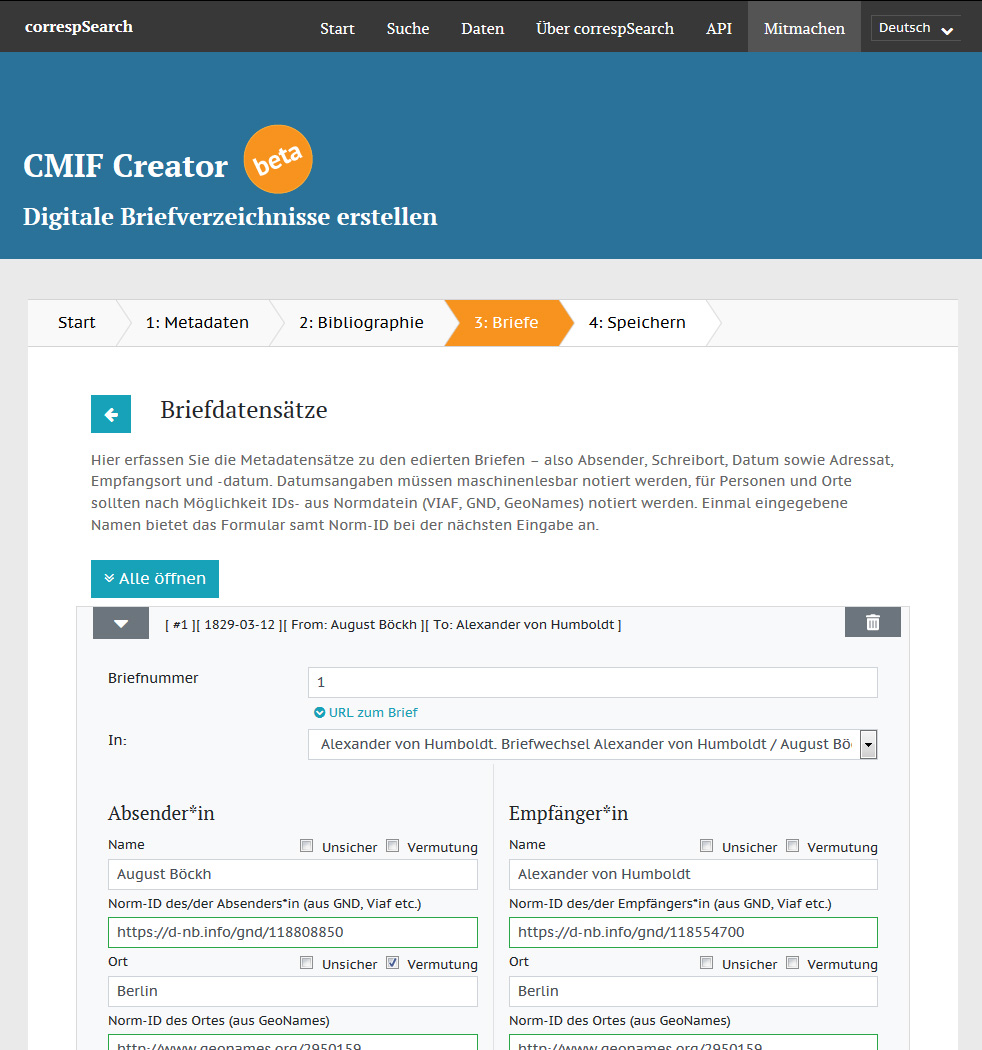
Die überwiegende Menge der Briefeditionen liegt auch im digitalen Zeitalter noch ausschließlich gedruckt vor. Um die edierten Briefe und die darin enthaltenen Informationen auch digital verfügbar zu machen, können Briefmetadaten im Correspondence Metadata Interchange Format (CMIF) bereitgestellt und mit dem Webservice correspSearch durchsucht werden. Waren bisher für die Erstellung von Briefverzeichnissen in CMIF XML-Kenntnisse notwendig, […]
weiterlesen
Im Rahmen des DH-Kolloquiums an der BBAW möchten wir Sie herzlich zum nächsten Termin am Freitag, den 2. Februar 2018, 17 Uhr s.t. bis 19 Uhr (Raum 230), einladen: Burkhard Meyer-Sickendiek und Hussein Hussein (beide FU Berlin) werden über „Rhythmicalizer. Ein digitales Werkzeug zur Prosodieerkennung in Hörgedichten“ referieren. Der Vortrag gibt zunächst einen Einblick in […]
weiterlesen
Vor kurzem ist das von der Deutschen Forschungsgemeinschaft (DFG) geförderte Projekt „correspSearch – Briefeditionen vernetzen“ gestartet. Im Rahmen des Projektes werden in den nächsten Jahren die Benutzeroberfläche, Suchfunktionalitäten und Schnittstellen des Webservices correspSearch weiterentwickelt und der Datenbestand erweitert.
weiterlesen
Im Rahmen des DH-Kolloquiums an der BBAW möchten wir Sie herzlich zum nächsten Termin am 6. Oktober 2017, 17 Uhr s.t. bis 19 Uhr (Konferenzraum 1), einladen: Dr. Andreas Kuczera (Akademie der Wissenschaften und der Literatur Mainz) wird über „Graphentechnologien in den digitalen Geisteswissenschaften“ referieren. Dabei wird er anhand verschiedener Beispiele aus den Projekten Regesta […]
weiterlesen
Die TELOTA-Initiative an der Berlin-Brandenburgische Akademie der Wissenschaften (BBAW) sucht zum nächstmöglichen Zeitpunkt eine wissenschaftliche Mitarbeiterin / einen wissenschaftlichen Mitarbeiter mit Erfahrungen in den Digital Humanities für das von der DFG geförderte Projekt „correspSearch – Briefeditionen vernetzen“. Aufgaben sind u.a. die Konzeption, Entwicklung und Implementierung von Workflows und Tools zur browserbasierten Erfassung von Metadaten in […]
weiterlesen
Der Webservice correspSearch weist mittlerweile knapp 16.000 edierte Briefe in über 60 digitalen und gedruckten Publikationen nach. Erst kürzlich sind neue Metadaten zu verschiedenen Korrespondenzen hinzugekommen, z.B. aus der Alfred Escher-Briefedition, die erst im letzten Jahr mit einem Relaunch abgeschlossen wurde. Auch das Zentrum für Informationsmodellierung in Graz hat die Metadaten seiner digitalen Briefedition “Alexander […]
weiterlesen
Die TEI Correspondence Special Interest Group lädt zum Workshop „Encoding correspondence meta data with correspDesc“ ein, der am Dienstag, den 27. Oktober 2015, im Rahmen der diesjährigen TEI-Konferenz in Lyon stattfinden wird. Im Workshop soll thematisiert werden, wie man in digitalen Editionen Korrespondenz-Metadaten mit Hilfe des neuen TEI-Elements <correspDesc> kodieren kann und wie man mit […]
weiterlesen
Die Projekte DTA und CLARIN-D laden zur kommenden zweiten gemeinsamen Konferenz ein, welche die Bedeutung, den Nutzen und die Möglichkeiten der Nachnutzung von „Textkorpora in Infrastrukturen für die Geistes- und Sozialwissenschaften“ behandelt. In zwei übergeordneten Themenblöcken stellen Wissenschaftlerinnen und Wissenschaftler verschiedener geistes- und sozialwissenschaftlicher Disziplinen zum einen aktuelle, korpusgeleitete Forschungsfragen und zum anderen verschiedene Zugriffs- […]
weiterlesen
Mit dem neuen Webservice „correspSearch“ können Verzeichnisse verschiedener digitaler und gedruckter Briefeditionen nach Absender, Empfänger, Schreibort und -datum durchsucht werden. Dafür stehen eine Website und eine Schnittstelle zur Verfügung.
weiterlesen
Seit 2012 wird von der TELOTA-Initiative an der Berlin-Brandenburgischen Akademie der Wissenschaften »ediarum« entwickelt und eingesetzt. Dabei handelt es sich um ein Paket aus drei Softwarelösungen (Oxygen XML, eXistdb und ConTeXt), das es Wissenschaftlern in verschiedenen Editionsvorhaben ermöglicht, ihre Ergebnisse in TEI-XML zu bearbeiten, zu speichern und zu präsentieren. Damit die Eingabe und Bearbeitung möglichst […]
weiterlesen